自己动手画 CPU《计算机组织与结构实验》(三)
# principle, 2020-10-19
三、存储系统设计
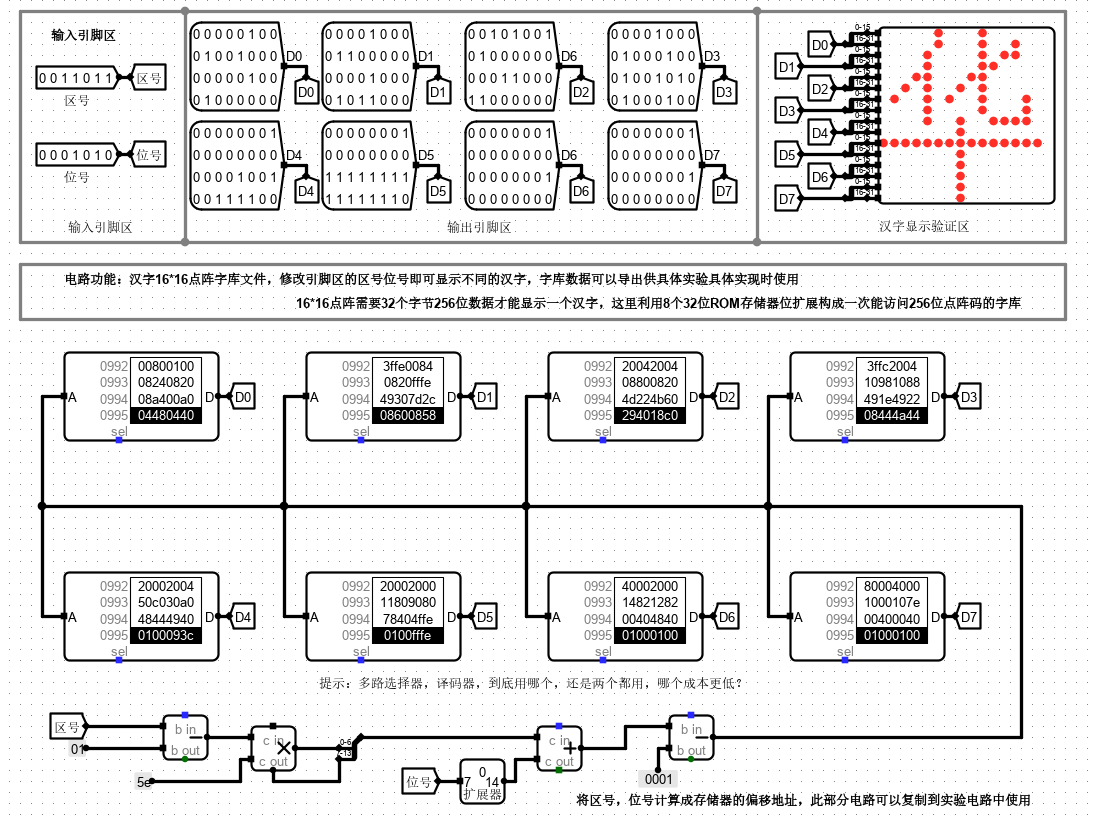
1、汉字字库存储芯片扩展实验
实验目的
理解存储系统进行位扩展、字扩展的基本原理,能利用相关原理解决实验中汉字字库的存储扩展问题,并能够使用正确的字库数据填充。
电路引脚
| 信号 | 输入/输出 | 位宽 | 说明 |
|---|---|---|---|
| 区号Qu | 输入 | 7 位 | 汉字区位码的区号 |
| 位号Wei | 输入 | 7 位 | 汉字区位码的位号 |
| Di | 输出 | 32 位 | 汉字点阵信息 |
汉字点阵为16*16位。需要8片16K32位ROM来存储点阵信息。
我们需要用 4 片 4 K 32 位 ROM代替其中一片 16 K 32 位ROM。
4K需要12根地址线,16K需要14根地址线。所以高位多余的两位作为片选信号。
我们需要一个数据选择器,来进行选择输出那一片ROM中的数据。
再根据数据进行分析,数据的最后两位是选片区的。所以将最后两位直接输入到选择器选择短。
最后将数据对应连接,及可得到电路。
参考字库采用 8 片 16 K 32 位 ROM 来存储点阵信息。
主要扩展方法:字扩展、位扩展、字位扩展
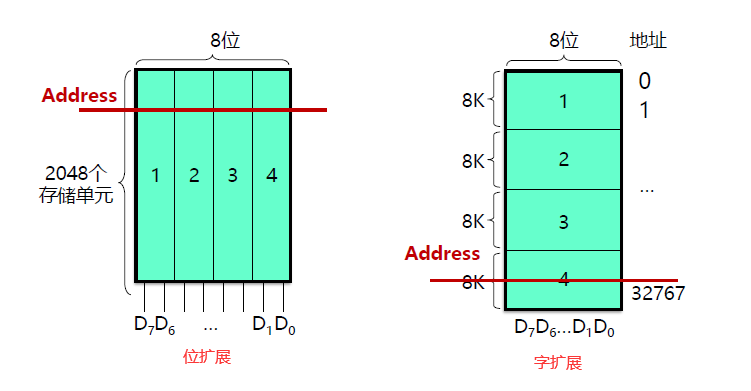
设存储空间为 M *** N 位,M 表示 M 根地址线,N 表示 N 根数据线。现有存储芯片是 m *** n 位。
若 M=m ,N>n,需要对芯片进行 位扩展。(数据线扩展,字长扩展)
若 M>m,N=n,需要对芯片进行 字扩展。 (地址线扩展, 字数扩展)
若 M>m,N>n,需要对芯片进行 字位扩展。
1、位扩展时:当 CPU 给出一个地址访问存储系统时,该地址被送入到所有的存储芯片中,所有芯片并发的工作,并提供各自的 2 位信息。
2、字扩展时:当 CPU 给出一个地址访问存储系统时,只有一个存储芯片工作,具体哪个芯片工作由存储系统地址高 2 位来决定。
由于此处是 4 片 4 K 32 位 ROM 代替其中 1 片 16 K 32 位ROM,因此需要采用字扩展。
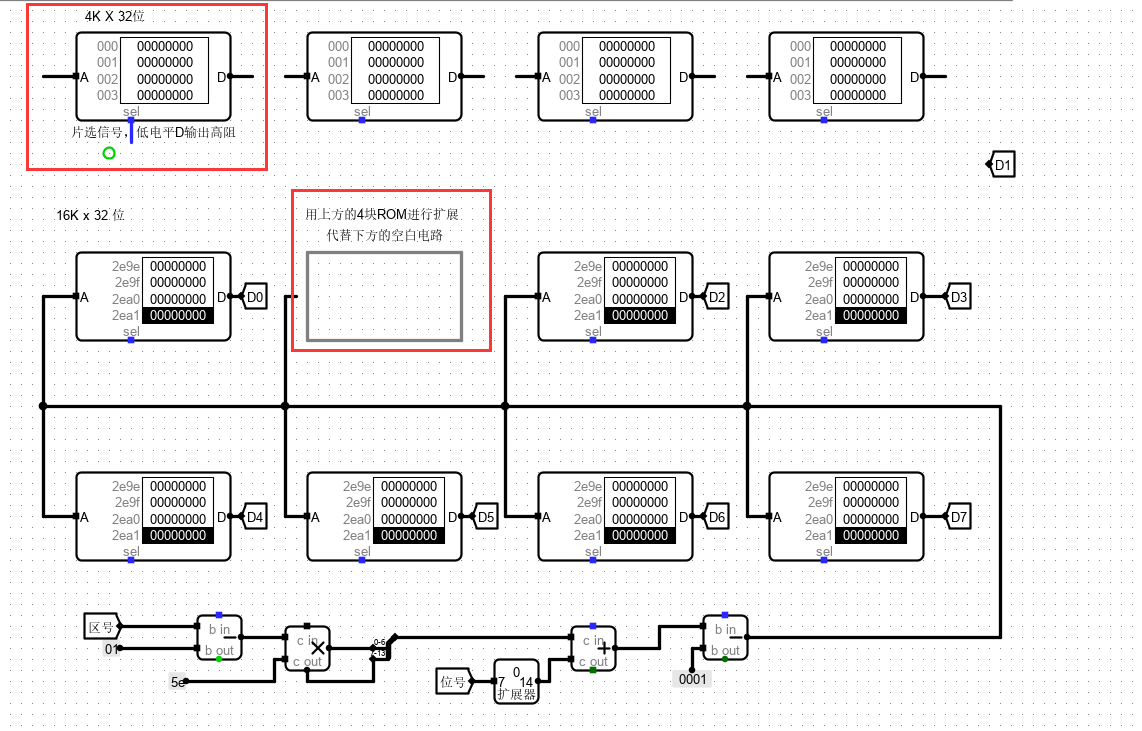
4 个 4K 变为 1 个 16K,需要的是串行输出某个指定的 ROM,因此通过一个多路选择器,来进行选择输出那一片ROM中的数据。
下图易发现,片选选择相应的 ROM。其余 12 位都输入一样的结果。在 7 片位扩展的 ROM 组中,并行计算,各自给出自身 ROM 中的相应数值,再拼凑起来。
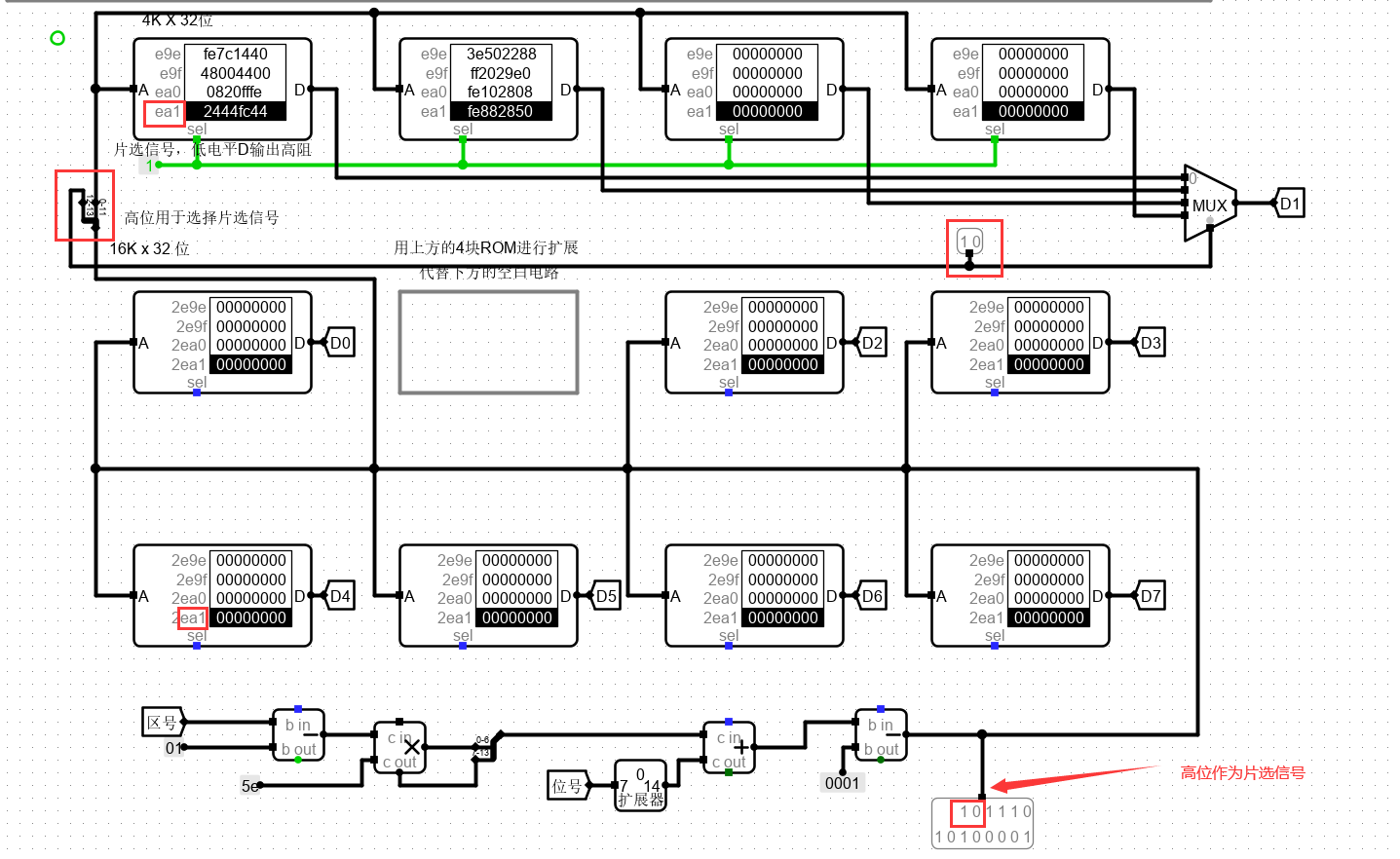
组合好电路之后,将示例中的 ROM 中的数据分别放到指定位置。值得注意的是:
0000-0ff0
1000-1ff0
2000-2ff0
3000-3ff0
分别为第一片 ROM 到 第四片的数据,依次复制到对应ROM中,即可展开测试。
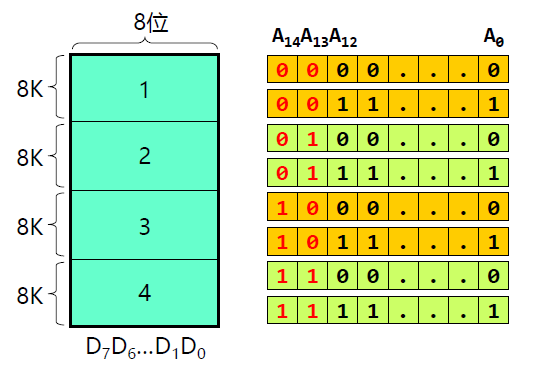
综合举例

因此由主存地址可知:
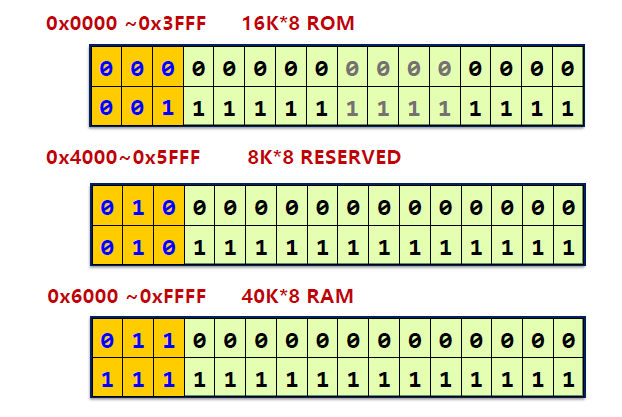
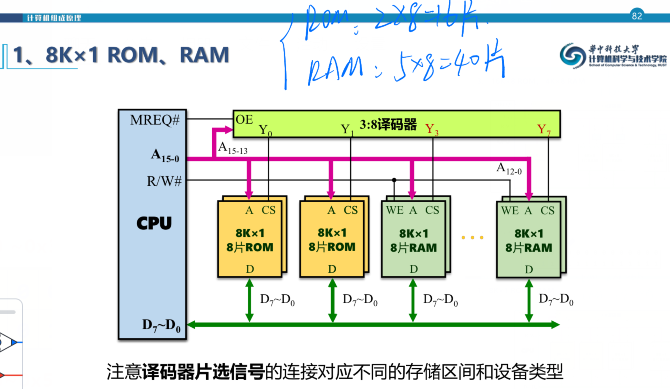
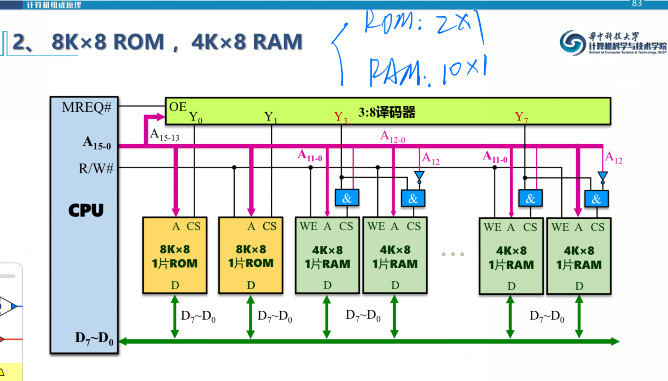
下面对几个情况进行图示:
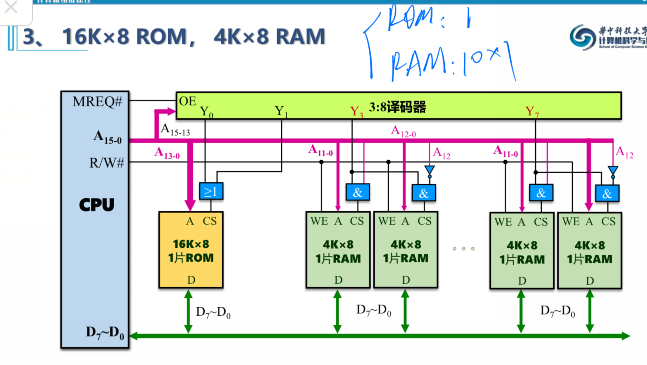
2、MIPS RAM 设计
实验内容
Logisim 中 RAM 组件只能提供固定的地址位宽,数据输出也只能提供固定的数据位宽,访问时无法同时支持字节/半字/字三种访问模式,实验要求利用4个8位的 RAM 组件进行扩展,设计完成既能按照8位、也能按16位、也能按照32位进行读写访问的32位存储器,最终存储器引脚定义如下表。
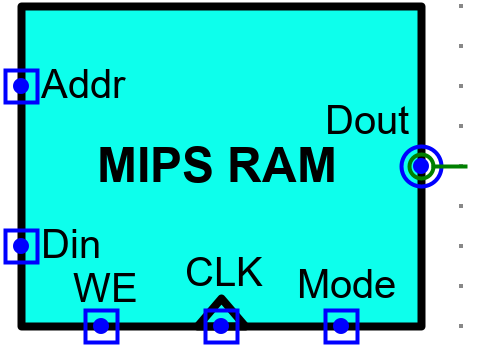
电路引脚
| 信号 | 输入/输出 | 位宽 | 功能描述 |
|---|---|---|---|
| Addr | 输入 | 12 | 字节地址输入(字访问时忽略最低两位,半字访问时忽略最低位,倒数第二位片选,字节访问时,低两位进行片选) |
| Din | 输入 | 32 | 写入数据 (不同访问模式有效数据均存放在最低位,高位忽略 |
| Mode | 输入 | 2 | 访问模式控制位(00 表示字访问,01 表示 1 字节访问,10 表示 2 字节访问) |
| WE | 输入 | 1 | 写使能,1 表示写入,0 表示读出 |
| Dout | 输出 | 32 | 读出数据 (不同访问模式有效数据均存放在最低位,高位补零); |
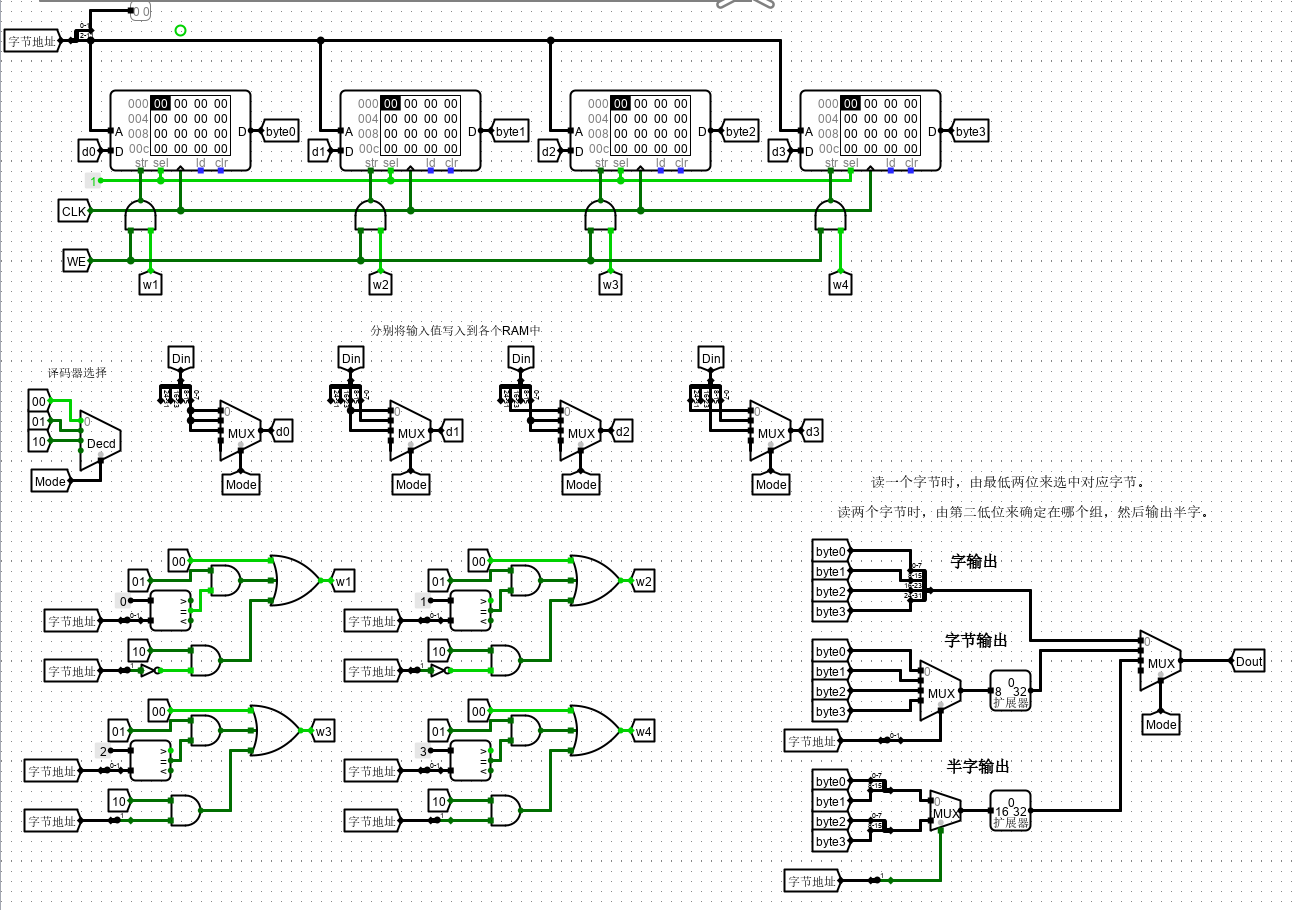
该实验需要完成既能按照8位、也能按16位、也能按照32位进行读写访问的32位存储器。如下图在不同要求时进行不同 byte 的选择。
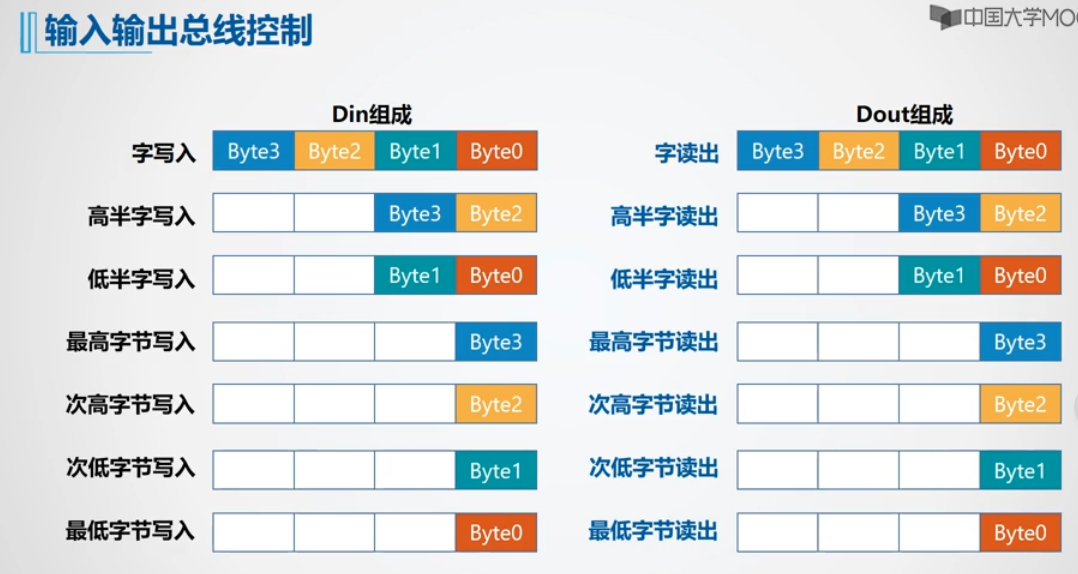
现在开始实验的分析
- 字地址,也就是 32 位地址,由 4 个字节组成,因此按字节编址的话,地址末尾一定是00。而半字地址,末尾一定是0。本实验的输入没有做严格限定,要求我们相应MODE下对地址进行对齐。
- load 信号一直有效,而写信号只有当 WE=1时才有效。
- 32位数据由 四片 RAM 并行工作给出,16位选高两片或低两片,8位则只需1片 RAM 工作。
- 给出的地址是字节地址,因此为了选中相应的 RAM ,需要取出后两位判断;为了取出相应的半字,需要对第二低位进行判断。
- 送入写入端的数据,根据 MODE 和 Din 的相关位生成
首先实现大框架展示
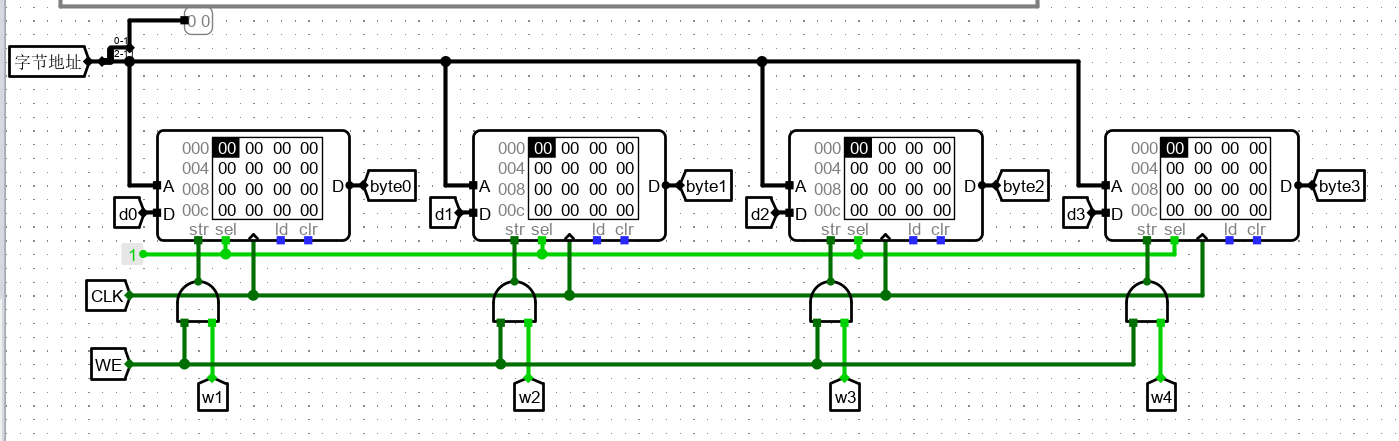
str信号由各 RAM 的 WE 信号 和 wi 信号 相与给出,表示仅当写模式下,且该 RAM 需要参与写时才有效。输入数据和输出数据分别由相应的通道给出,方便后续控制。
wi 表示此时是否选择该组件写入。di 表示此时选择该组件输入时写入的数据。
sel 为0 禁用组件,因此置为 1 或者 悬空都可。
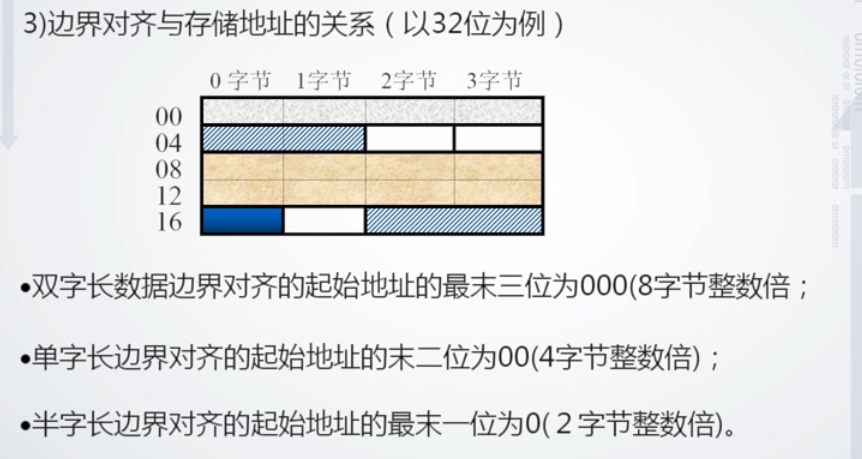
1、load
首先说明当为 load 时,如何读出。
最简单的就是字读出,当模式为字读出时,直接输出全部数据即可。
半字读出时,我们由字节地址第二低位来决定输出哪个半字。
字节读出时,我们由字节地址低两位来决定输出哪个字节。0 表示 01 位、1 表示 23 位。
2、写入 store
由之前的框架图
可知:
- str 信号由各 RAM 的 WE 信号 和 wi 信号 相与给出,表示仅当写模式下,且该 RAM 需要参与写时才有效。输入数据和输出数据分别由相应的通道给出,方便后续控制。
- wi 表示此时是否选择该组件写入。di 表示此时选择该组件输入时写入的数据。
1、wi 是否选择该组件
考虑一下什么情况下这个 RAM 需要写入数据。
- 字 00 写入时肯定所有 RAM 都要写入;
- 半字 10 写入时,只有当前片被选中才需要写入;
- 单字节 01 写入时,只有指定了当前片才需要写入。
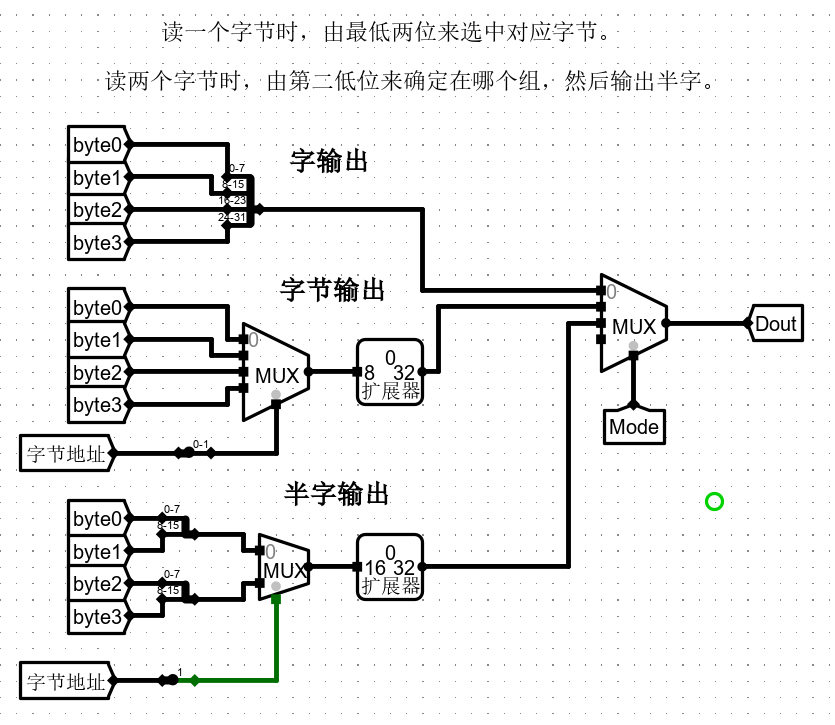
- 现在通过 mode 的译码器,作为 模式 的选择
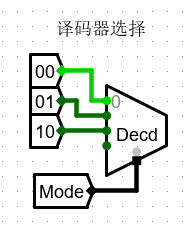
于是可以构造以下的电路:
当 mode = 00 时,所有片选信号都要为真,进行写入
当 mode = 01 时,字节地址最低两位 和 所选择的 RAM 编号相一致时,进行写入。
当 mode = 10 时,字节地址的倒数第二低的一位来决定选择哪两片。当这一位等于0,应该选择01号组合,否则选择23号组合。
- 因此值得注意的是,在mode 为 10 时,在 RAM 编号为 0、1时需要取反。(理由如上)
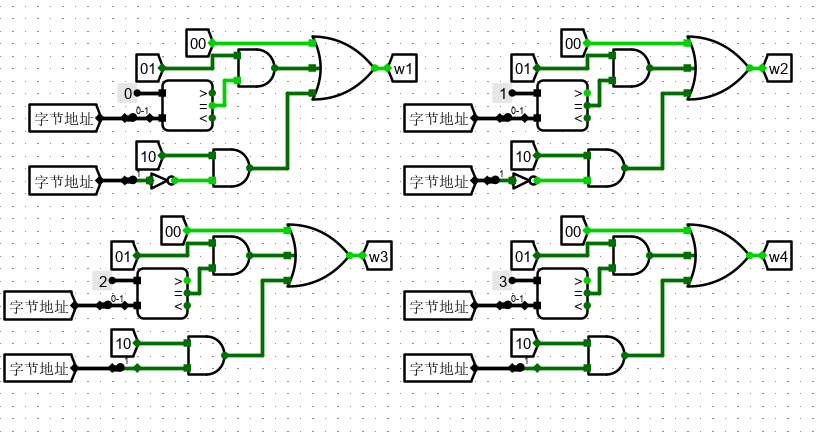
2、di 表示此时选择该组件输入时写入的数据
di 的输入取决于 mode 的输入,然后对 Din 值进行选择。
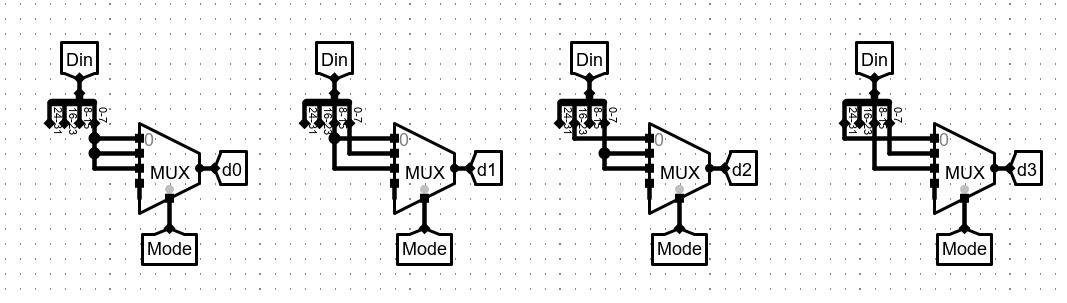
如果 mode 为 字 写入(00),从 d0-d3 分别输入 0-7,8-15,16-23,24-31 位数据。
如果 mode 为 字节 写入(01),会写入 Din 的 0-7 位数据,所以我们将 d0-d3 都输入 0-7 位数据。至于选哪片RAM 写入,由写的片选信号决定。
如果 mode 位 半字 写入(10),会写入 Din 的 0-15 位数据,因为我们必须实现对齐,所以无论是01号组合,还是23号组合,较低编号一定存放低位数据,反之存放高位数据,所以d0,d2输入0-7位数据,d1,d3输入8-15位数据。
注意 可结合大端小端进行深入思考
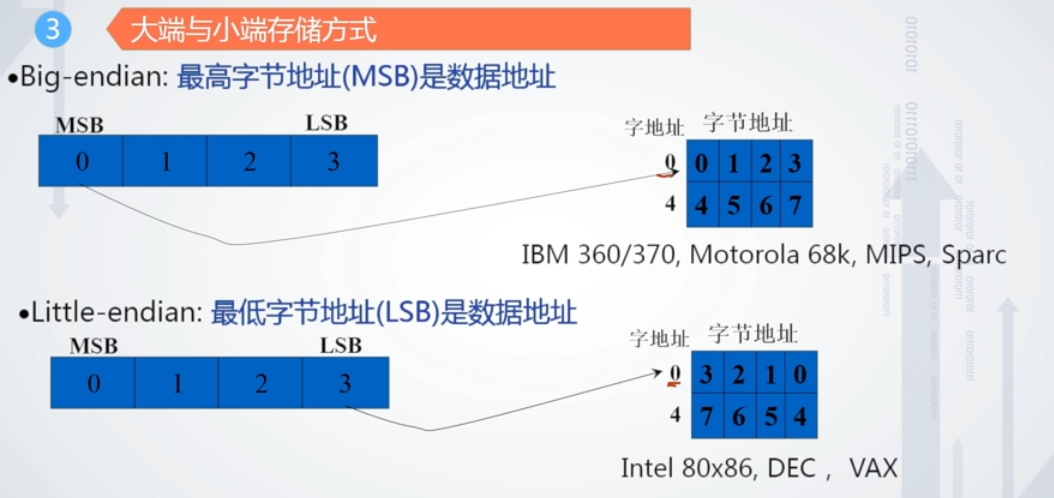
但是无论大端小端,每个系统的内部是一致的,但在系统间进行通信时,会发生问题。因此需要进行顺序的转换。

最终电路实现如下
3、MIPS 寄存器文件设计
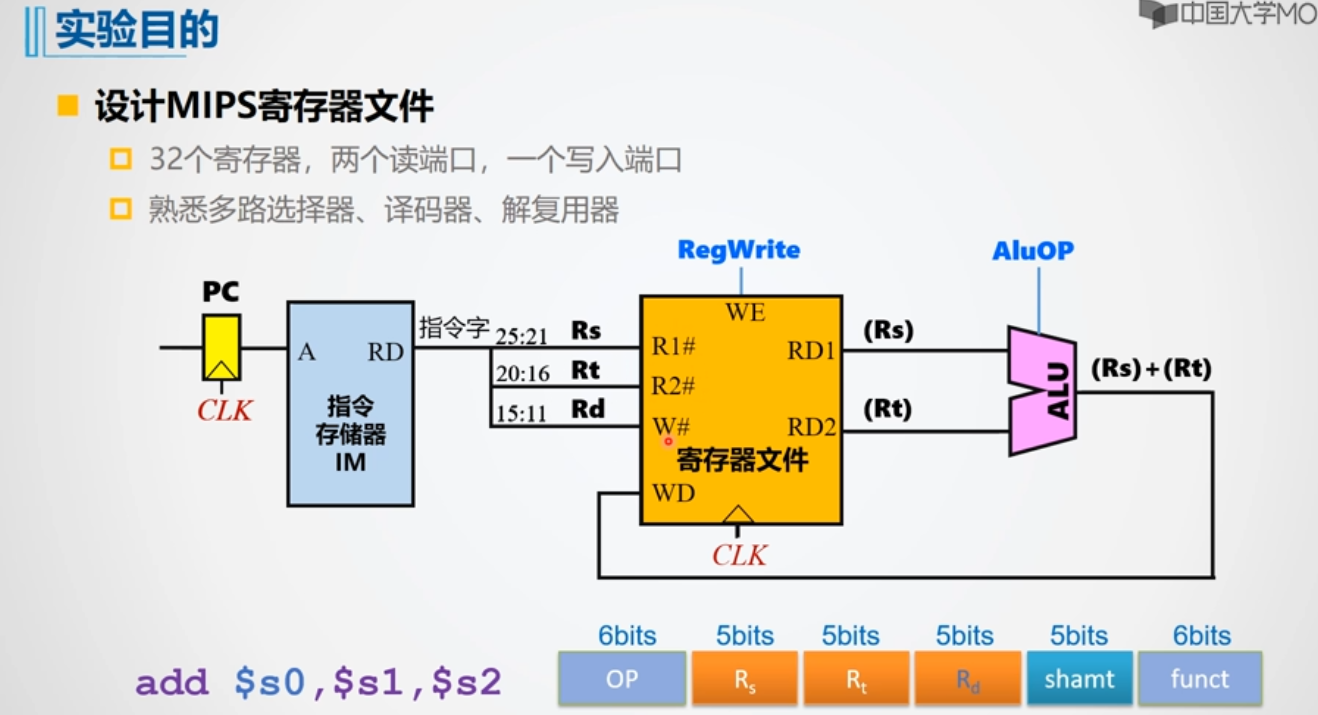
实验目的
利用 Logisim 平台构建一个简化的 MIPS 寄存器文件,内部包含4个32位寄存器,其具体引脚与功能描述如下表。
引脚介绍
| 信号 | 输入/输出 | 位宽 | 功能描述 |
|---|---|---|---|
| R1# | 输入 | 5 | 第 1 个读寄存器的编号 |
| R2# | 输入 | 5 | 第 2 个读寄存器的编号 |
| W# | 输入 | 5 | 写入寄存器编号 |
| Din | 输入 | 32 | 写入数据 |
| WE | 输入 | 1 | 写使能信号,为 1 时在 CLK 上跳沿将 Din 数据写入W#寄存器 |
| CLK | 输入 | 1 | 时钟信号,上跳沿有效 |
| RD1 | 输出 | 32 | R1# 寄存器的值,MIPS 寄存器文件中 0 号寄存器的值恒零 |
| RD2 | 输出 | 32 | R2# 寄存器的值,MIPS 寄存器文件中 0 号寄存器的值恒零 |
注意R1#R2#W#,为了简化,只有 2 位位宽,这样便可以在 0-3 号寄存器中选择。其中 0 号寄存器的值恒零。
首先实现读逻辑。
R1# 和 R2# 为两位位宽,设置数据选择器的位宽为两位。这样就可以通过 R1# 和 R2# 决定 RD1 和 RD2 取指定编号寄存器中的值。
如:R1#:10 表示 2 号寄存器
每个寄存器连接上对应输出,把输出接到上面的两个数据选择器的数据输入端即可。
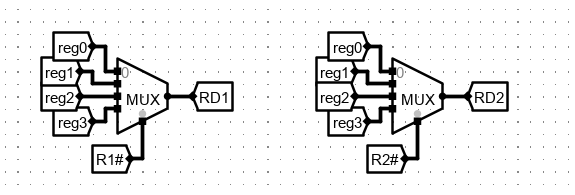
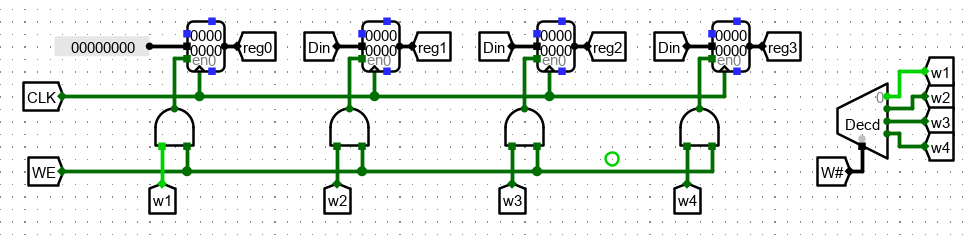
接下来实现写逻辑。
一共有 4 个寄存器,所以通过译码器,将 W# 转换为4个片选信号。分别表示 0-3 号寄存器。
当 WE 为1时,表示可以写入数据。所以将片选信号和 WE 用与门连接。
最后将数据输入对应,即可得到电路。
另外,要注意0号寄存器要保持恒零,所以数据输入也要为零。
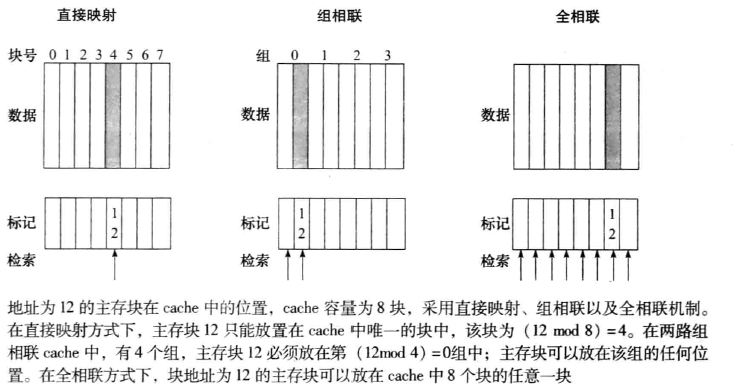
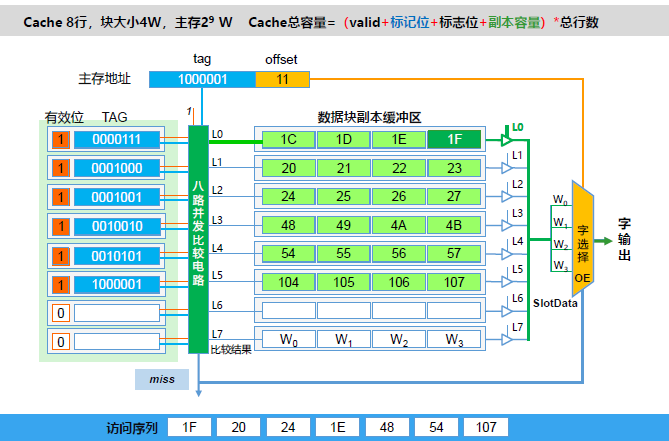
直接相联、组相联、全相联直观区别:
4、直接相联 Cache 设计
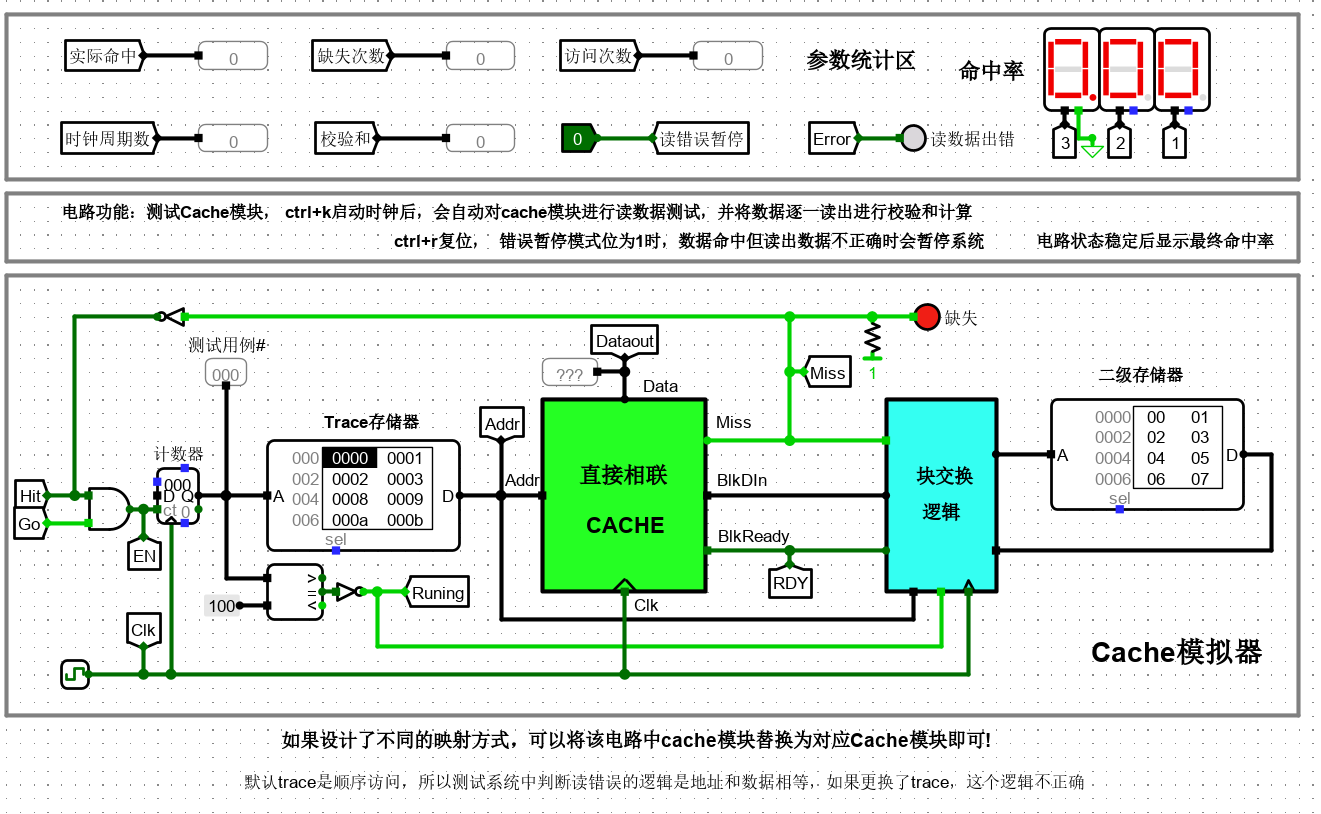
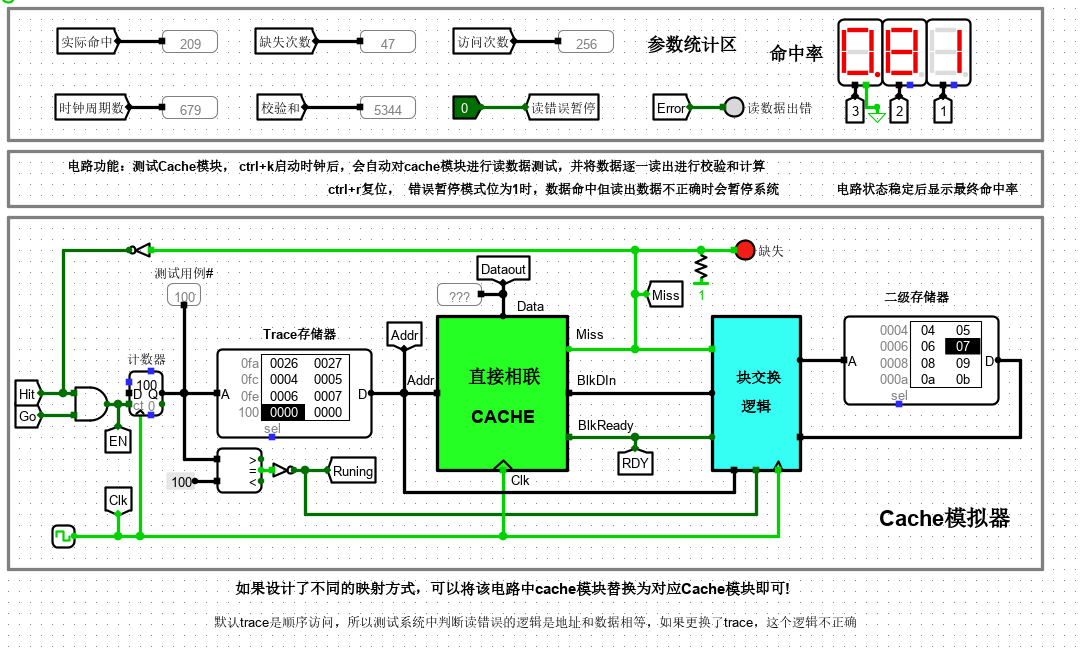
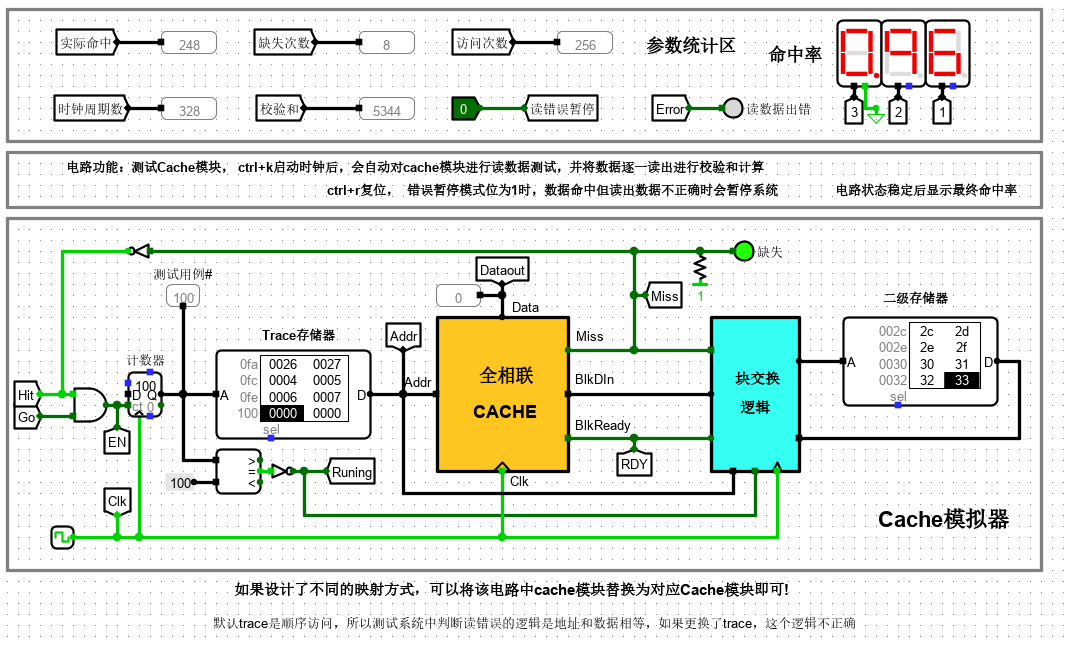
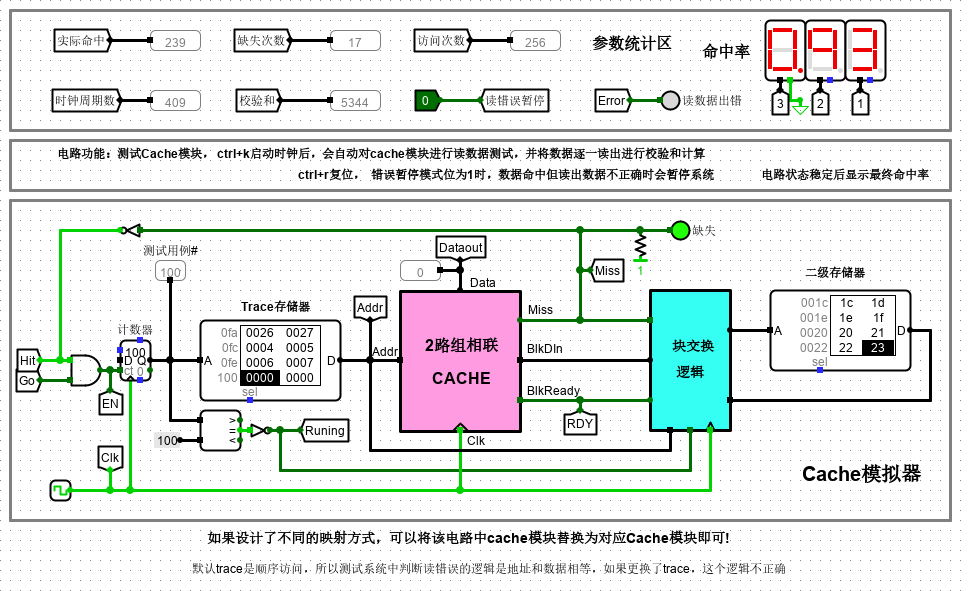
上图给出了一个在 Logisim 中设计完成的 cache 系统自动测试电路,为简化实验设计,这里所有 cache 模块均为只读 cache(类似指令 cache),无写入机制。电路左侧计数器与存储器部分会在时钟驱动下逐一生成地址访问序列给 cache 模块。计数器模块的使能端受命中信号驱动,缺失时使能端无效,计数器不计数,等待系统将待请求数据所在块从二级存储器中调度到 cache 后才能继续计数。cache 与二级存储器之间通过块交换逻辑实现数据块交换,由于二级存储器相比 cache 慢很多,所以一次块交换需要多个时钟周期才能完成,cache 模块判断数据块准备好的逻辑是 blkready 信号有效,该信号有效且时钟到来时,cache 将块数据从 BlkDin 端口一次性载入到对应 cache 行缓冲区中,此时 cache 数据命中,直接输出请求数据,解锁计数器使能端,继续访问下一个地址。
电路引脚
| 信号 | 输入/输出 | 位宽 | 功能描述 |
|---|---|---|---|
| Addr | 输入 | 16 | 主存地址 |
| BlkDataIn | 输入 | 32 | 块数据输入 |
| BlkDataReady | 输入 | 1 | 块数据准备就绪 |
| CLK | 输入 | 1 | 时钟输入 |
| Miss | 输出 | 1 | 1:数据缺失;0:数据命中 |
| DataOut | 输出 | 8 | 数据输出 |
1.直接相联介绍
块映射速度快 ,一对映射 一对映射 ,无须查表 无须查表
- 利用索引字段直接对比相应标记位即可
- 查找表可以和副本一起存放 ,无需相联存储器
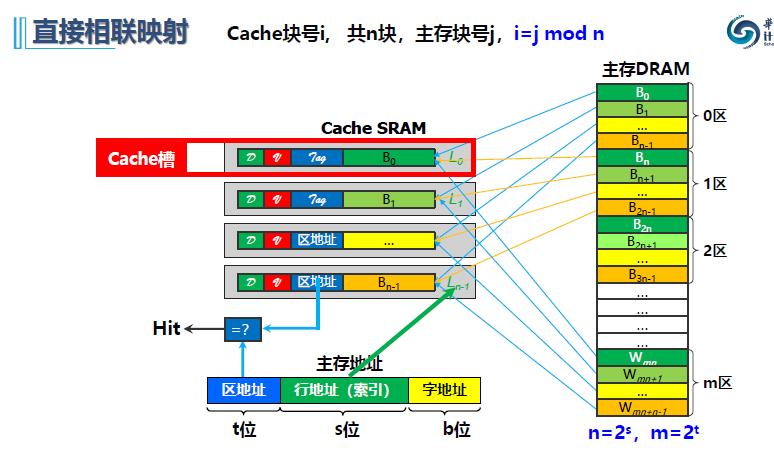
如下图所示:
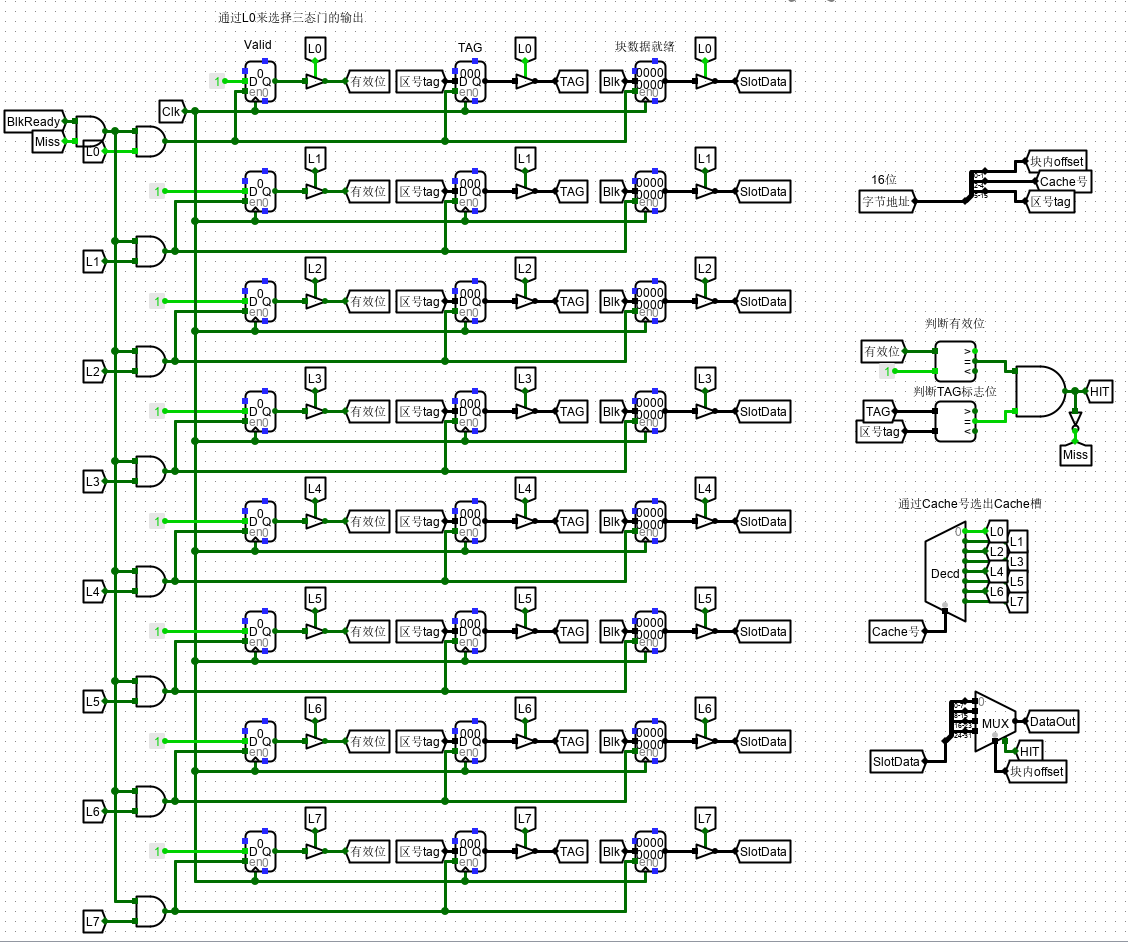
直接相联只用设计:字节地址和cache槽的设计、写入和写出设计、比较设计。
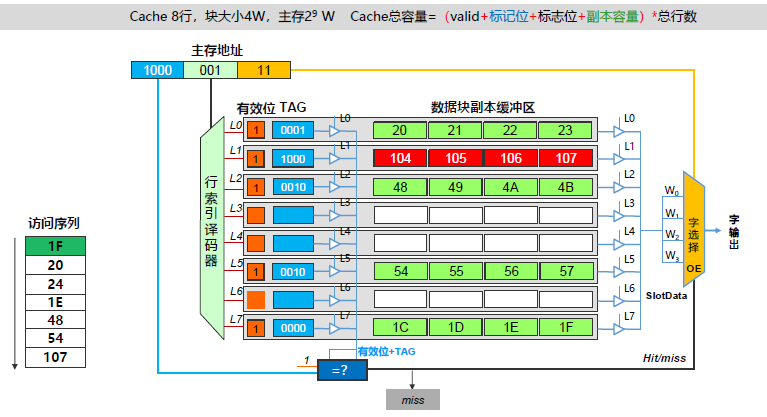
2.实验步骤
1、字节地址设计
由下图可知,输入到 直接相联映射的 Cache 槽前半部分(主存地址)为 16 位,直接映射分为 块 + 行 + 块内字节偏移
而 共要设计 8 块 Cache 槽,2^3 = 8,即 行占 3 位
又因为块数据输入为 32 位 即 4 字节,而由于输出 Dataout 为 8 位,即按照 字节 进行输出,因此 行内字节偏移 在 Cache 槽中占 2 位。
其余 11 位全部作为区号 tag
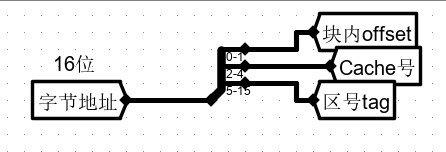
先将主存地址进行分割,作为 Cache 槽的前半部分。
2、Cache槽的设计
现在开始设计 Cache 槽。cache 主要包含四部分:Valid标志、主存 Tag 标记位、淘汰计数标记、数据副本。而我们需要考虑的是前三部分(直接相联没有淘汰计数,直接覆盖之前的 mod 数据),并且这三部分和之后的设计息息相关。
- 当中 valid 位有效位,判断该 cache 槽是否被命中过,存入了数据;
- Tag 位是存入的主存标记位;
注意:三态门
3、Cache 槽号译码器选择相应行
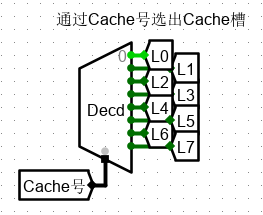
4、首先完成判断是否命中
通过有效位的判断 和 标志位(即此处的区号)判断,来进行 HIT 和 MISS 的判断。也就是说,只有当前组(块映射的Cache槽组) 和 当前行 同时被选中时,才能判断 HIT。
值得注意的是,此处三态门全部由 行选信号进行判断。
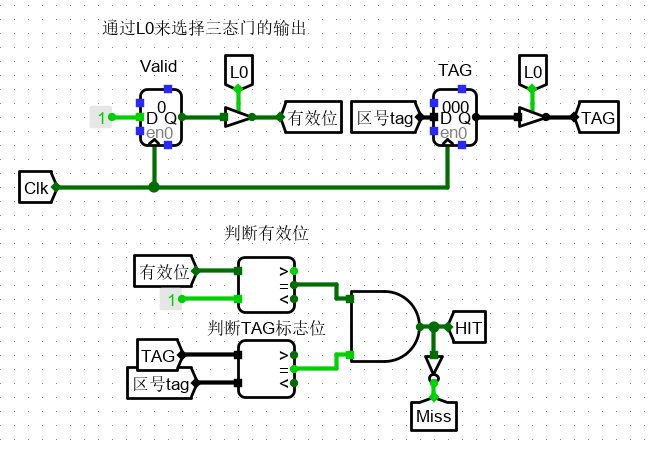
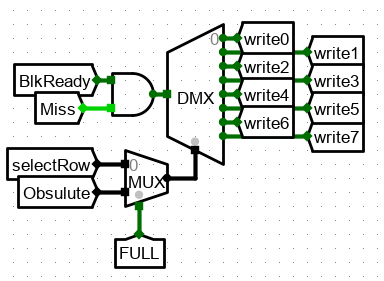
5、若未命中,需要进行读入数据
写入设计则要当 BlkReady 数据准备完成时(测试电路中的数据准备)选择具体的 cache 行进行写入,而写入的前提是该行为空,即 Miss 信号有效,才能写入数据。
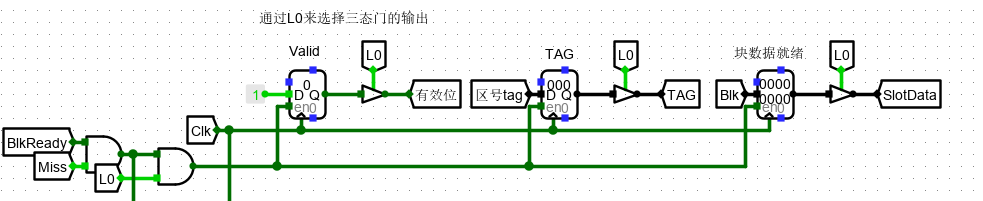
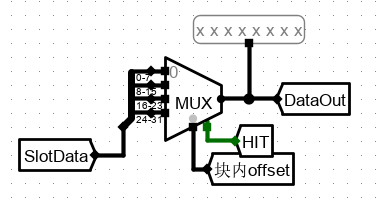
6、选择 Cache 槽中数据行对应字节
最后选择 SlotData 的 数据行中,根据行中偏移地址 offset 选出4 个字节中所需的一个。
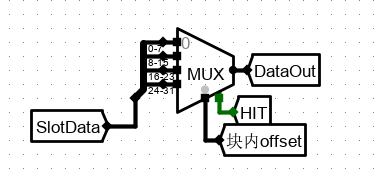
HIT 作为 命中判断,若没有命中,就不会选出。
遇到问题
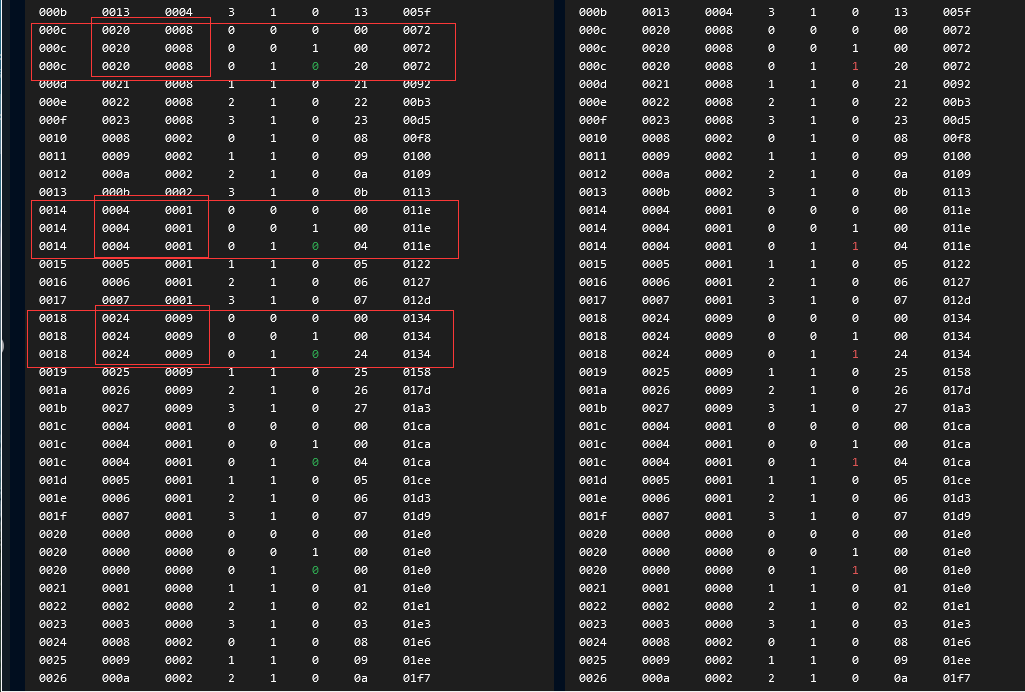 预期和我的实际输出不同在于,缺失后,从二级存储器载入数据后,本来此时 blkok 信号应该为0,但是现在为什么还是显示 块数据 blkok为 1啊?
预期和我的实际输出不同在于,缺失后,从二级存储器载入数据后,本来此时 blkok 信号应该为0,但是现在为什么还是显示 块数据 blkok为 1啊?
经过 8 小时的探寻,终于找到问题!!!
寄存器的触发方式分为上升沿、下降沿、高电平、低电平。
- 上升沿 : 当时钟信号从 0 到 1 变化时,寄存器更新其值
- 下降沿 : 当时钟信号从 1 到 0 变化时,寄存器更新其值
- 高电平:当时钟信号为 1 时,寄存器不断更新其值
- 低电平:当时钟信号为 0 时,寄存器不断更新其值
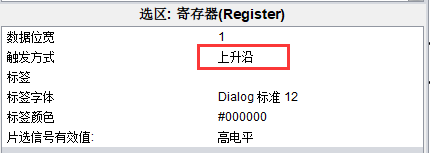
而由于此处的自动测试电路中,所有的计数器、寄存器全为 上升沿,因此应当将 直接相联 中的 寄存器也改为 上升沿!
最终完成电路
最终成果展示
3.直接相联特点
- 块映射速度快 ,一对一映射, 无须查表
- 利用索引字段直接对比相应标记位即可
- 查找表可以和副本一起存放 ,无需相联存储器
- cache 容易冲突 ,cache利用率低
- 淘汰算法简单
- 命中率低 ,适合大容量 cache
5、全相联 Cache 设计
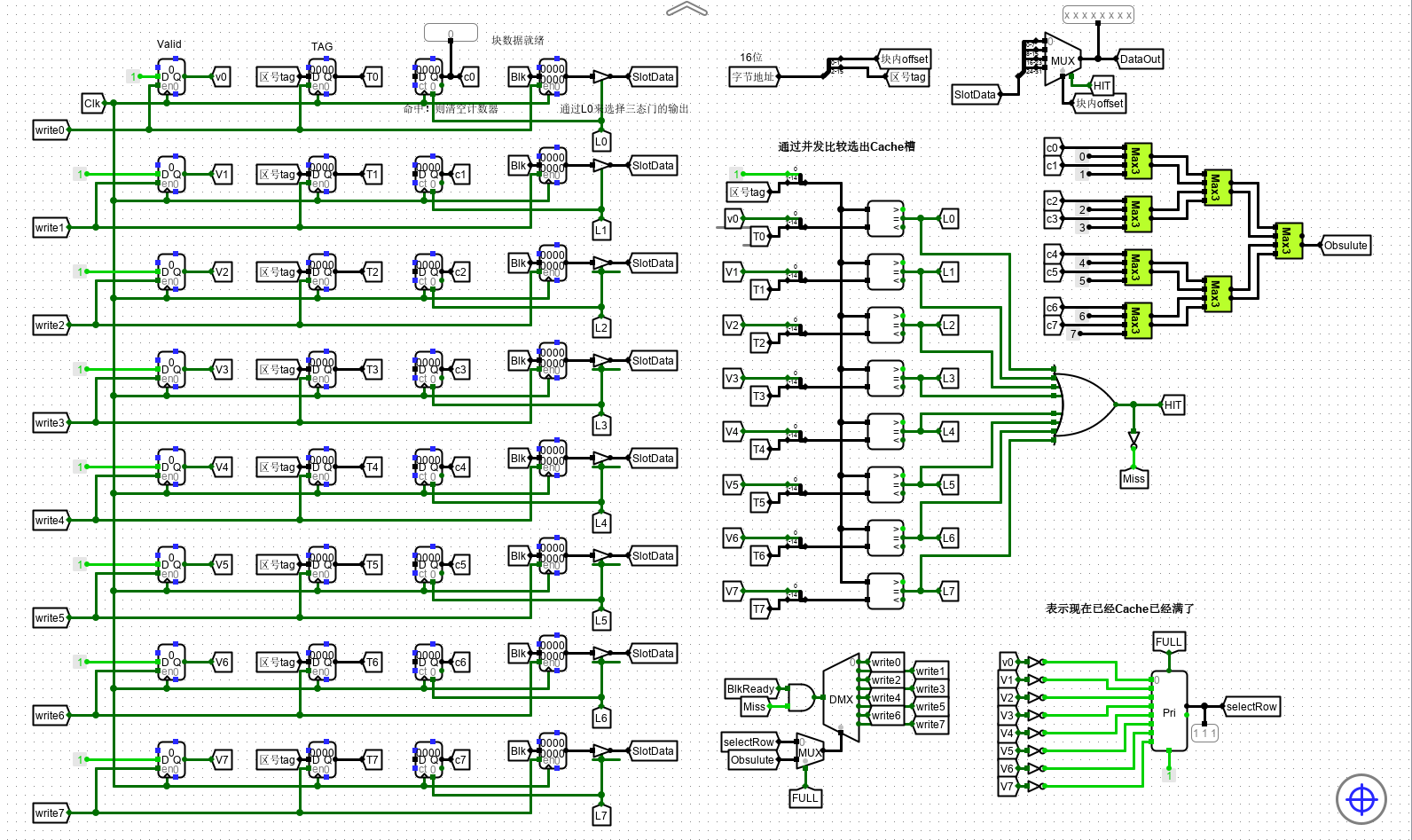
1.全相联介绍
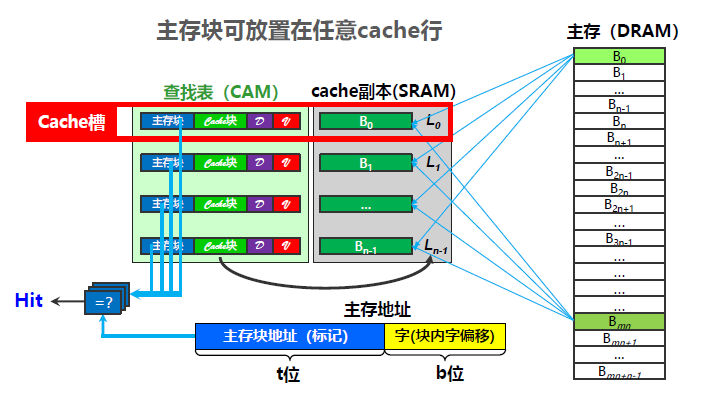
全相联映射是主存地址随机存储在任意的cache行,也就是只要是空行就可以进行存储,没有选择。然后通过标记位地址与8个cache槽中的标记位进行比较,判断是否命中,选择具体的1个cache槽;再通字内偏移地址,选择该cache槽中的单个字节来进行写入和写出的操作。
全相联映射需要做好淘汰算法。此处采用 LRU :数据淘汰时,应采用 LRU 计数器值最大的 Cache 行 进行淘汰。为提升速度,需要若干个比较器并发比较。
Cache 分为 CAM 和 SRAM 两部分。
字节地址和cache槽的设计、写入和写出设计、比较设计、淘汰算法设计。
2.实验步骤
1、字节地址设计
由下图可知,输入到 全相联映射的 Cache 槽前半部分(主存地址)为 16 位,直接映射分为 标志位 + 块内字节偏移
因为块数据输入为 32 位 即 4 字节,而由于输出 Dataout 为 8 位,即按照 字节 进行输出,因此 行内字节偏移 在 Cache 槽中占 2 位。
其余 14 位全部作为区号 tag
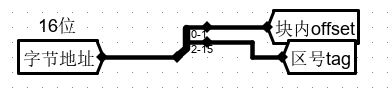
先将主存地址进行分割,作为 Cache 槽的前半部分。
2、Cache槽的设计
现在开始设计 Cache 槽。cache 主要包含四部分:Valid标志、主存 Tag 标记位、淘汰计数标记、数据副本。而我们需要考虑的主要是前三部分,并且这三部分和之后的设计息息相关。
- 当中 valid 位有效位,判断该 cache 槽是否被命中过,存入了数据;
- Tag 位是存入的主存标记位;
- 淘汰计数是一个计数器,初值为0,若行命中标志 Li 有效时,读入数据 0,达到清零的效果,若Li无效,则随着时钟频率一直进行计数。(与后面的淘汰算法密切相关)。而数据副本通过三态门缓冲器连接到总结上,这里三态门缓冲器的作用是当Li行有效时,将数据副本中输出的数据进行缓存,也就是使8个chche槽中的数据都可以缓存到1个Solt,这里就实现了总线的作用,十分优化。 这里给出了一个cache槽,其余的进行类似的复制。
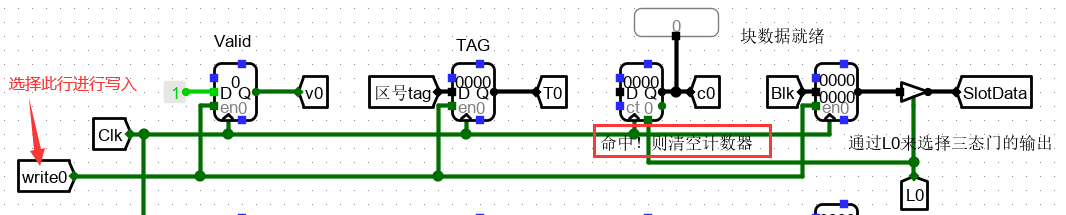
值得注意的是:
-
为什么直接相联映射采用 L0 控制 V0、T0 的三态门,全相联直接输出?
因为此时 L0 由 V0 和 T0 决定 ,而之前采用的是 Cache 选择控制(直接相联由 字节地址中的 第 2-4 位直接选择 Lx,而全相联需要并发比较各个标志位进行选择),此处为避免死循环,就不采用三态门。
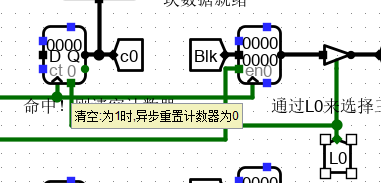
-
计数器的清空设置:
如下图,当选择该行时,需要将计数器重置。
3、写入和写出设计
-
写出设计即通过字内偏移地址 Offset 进行选择总线 Slot 上的某一字节进行输出。
-
写入设计则要当 BlkReady 数据准备完成时(测试电路中的数据准备)选择具体的cache行进行写入,而写入的前提是该行为空,即 Miss 信号有效,才能写入数据。
-
写入行的判断
- 若存在空行,即 FULL 信号无效,则选择相应的空行进行写入;
- 若FULL信号有效,则选择淘汰的行进行写入。两种情况都为之后的淘汰算法中选出的行号。
4、判断是否命中。————即比较设计
对于第 3 点的写入写出需要进行判断,即比较设计来判断是否命中。
不同的映射模式最大的区别就在于比较设计上。全相联因为是随机选取的 cache 行进行写入,因此没有行地址(索引),因此直接进行 8 个 cache 槽的并发比较,得到命中的cache行Li,并给出Miss和Hit信号。比较方法如图所示。
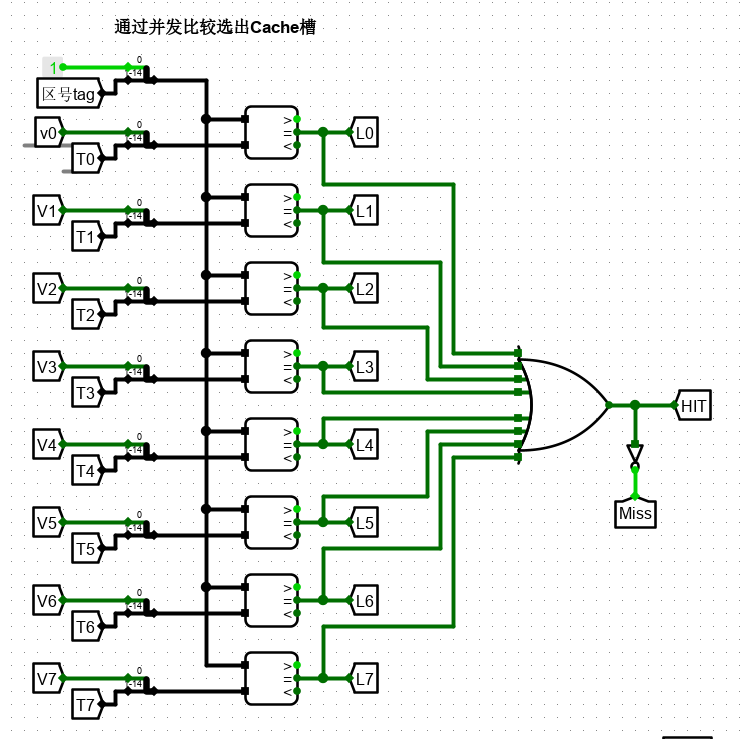
若命中,那么 HIT 信号为 1 ,则开始上文提到的 SlotData 输出显示。
若没有命中,那么 Miss 变为 1 ,开始进行淘汰算法,来选出相应的行。
5、淘汰算法
淘汰算法分为两个部分,
- 一个是当存在 cache 槽为空,空行的选择;
- 一个是当 cache 槽满时,淘汰行的选择
-
槽存在空
在空行的选择中,通过优先比较器来实现,优先比较器通过比较,输出的是索引较大的非 0 行,因此先对所有行的标志位取反,取反后,若为1,则表示该行为空;若为0,则表示该行已经存在数据。若所有行都存在数据则 FULL 行满信号有效。
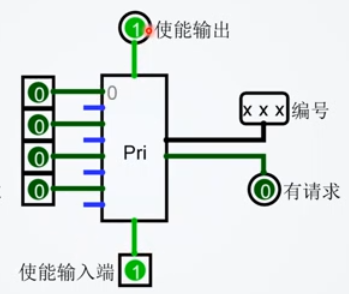
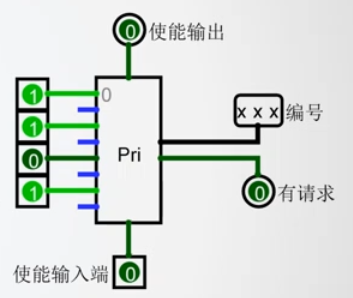
优先编码器
- 当多个引脚同时为 1 时,输出最大的那个编号
- 当使能端为
优先编码器组件还包含一个 使能输入端 和 使能输出端 。
- 只要 使能输入端 为 0 ,则该组件处于关闭状态,输出为不确定值。
- 当使能输入端为1,且输入引脚都不是1,则使能输出为 1 。
- 因此,可以串联两个优先编码器,使第一个编码器的使能输出端连接到第二个编码器的使能输入端。
- 如果第一个编码器有任意一个输入引脚值为1,则第二个优先编码器将会被关闭,输出为不确定值。
- 当第一个编码器没有引脚输入为1时,其输出为不确定值,此时第二个编 码器将会被开启,并输出最高优先级请求(输入为1)的编号。
- 优先编码器的这种设计,可以方便地将多个优先编码器串联起来使用以达到扩充输入的目的。
- 优先级编码器的另外一个输出(右下角)表示优先编码器有输入请求,当优先编码器使能输入为 1 ,且输入引脚中有 1 时,其输出为1。当多个优先编码器串联在一起使用时,这个输出可以用于判断哪个优先编码器被触发。
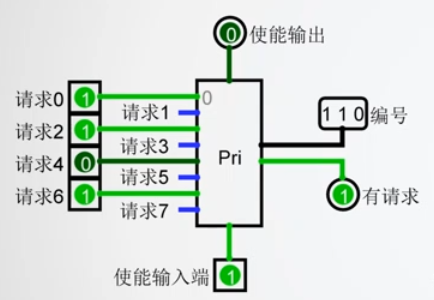
通过优先编码器选出索引值最大空Cache槽,或者输出 FULL
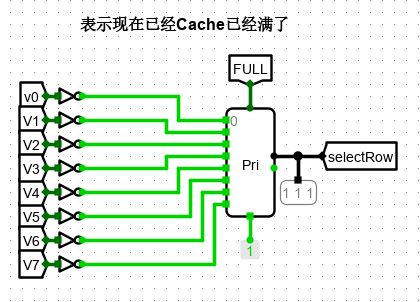
-
槽满时
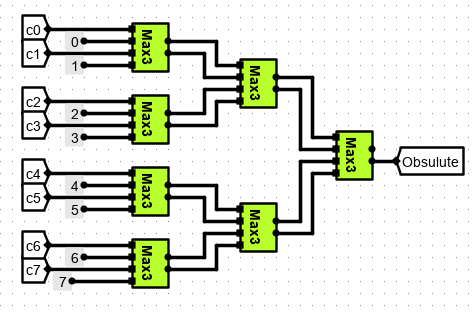
在淘汰行的选择中,主要运用到LRU淘汰算法(即最近最少使用淘汰算法),由于我们在 cache 槽设计中的计数器是当行选中时清零,行为选中时随时钟频率进行计数,因此这里计数的最大值即为最少使用的cache槽。 而我们用文件中附带的归并算法,这里的归并算法是输出两个值中较大的一位的数据和索引,最后得到相应的淘汰行。
由于是要输出 三位编码,因此选择 MAX3,其内部电路如图所示
其中 Y# 是指明 三位长度(12字节)的编号。只是为了后面的译码器根据选出的 三位长度 地址进行位号选择。
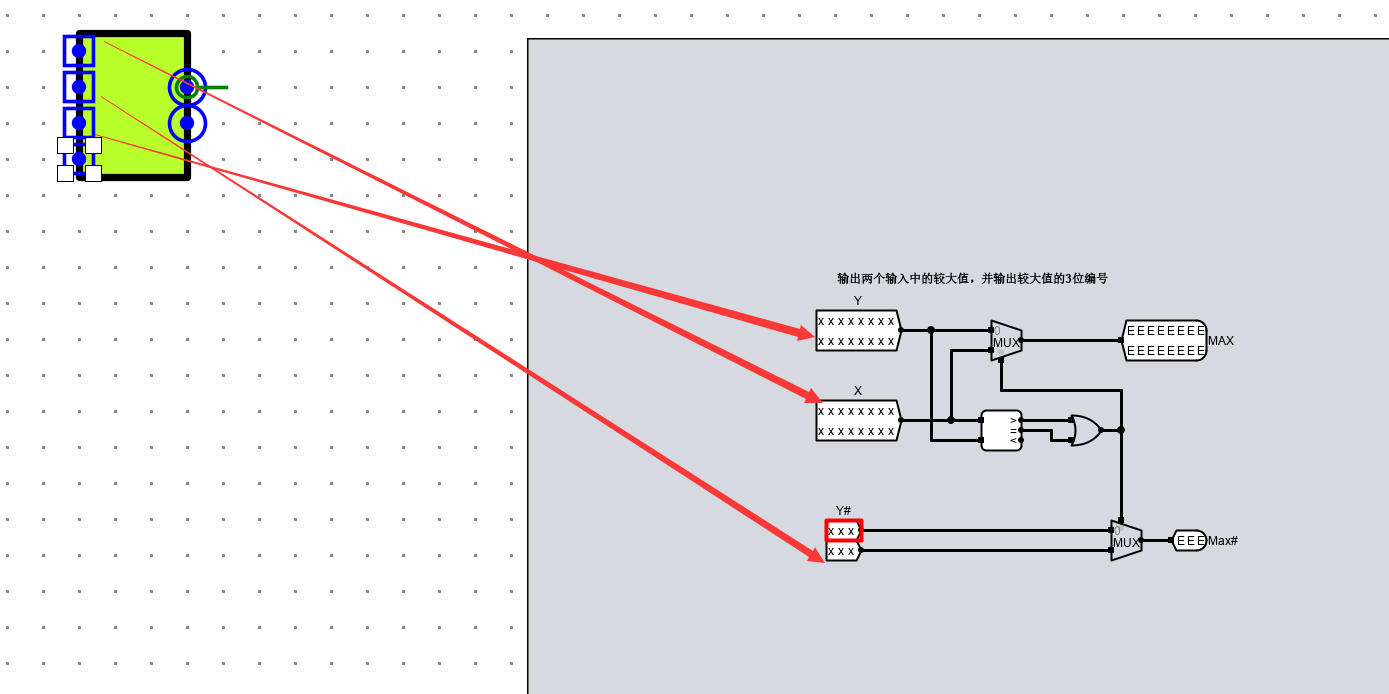
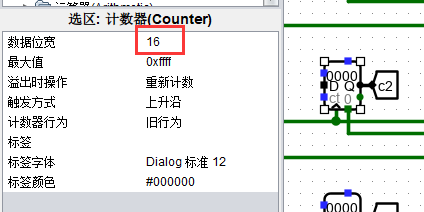
且由于此处提供的 MAX3 进行比较的数值( cnt 时钟计数)为 16 字节长度。因此计时器记录为 16位长度。
并发淘汰比较如下
最终电路实现如下
最终成果展示
3.全相联特点
- 块映射灵活 ,一对多映射
- cache全部装满后才会出现块冲突
- 块冲突的概率低 ,cache 利用率高
- 淘汰算法复杂
- 命中率高。
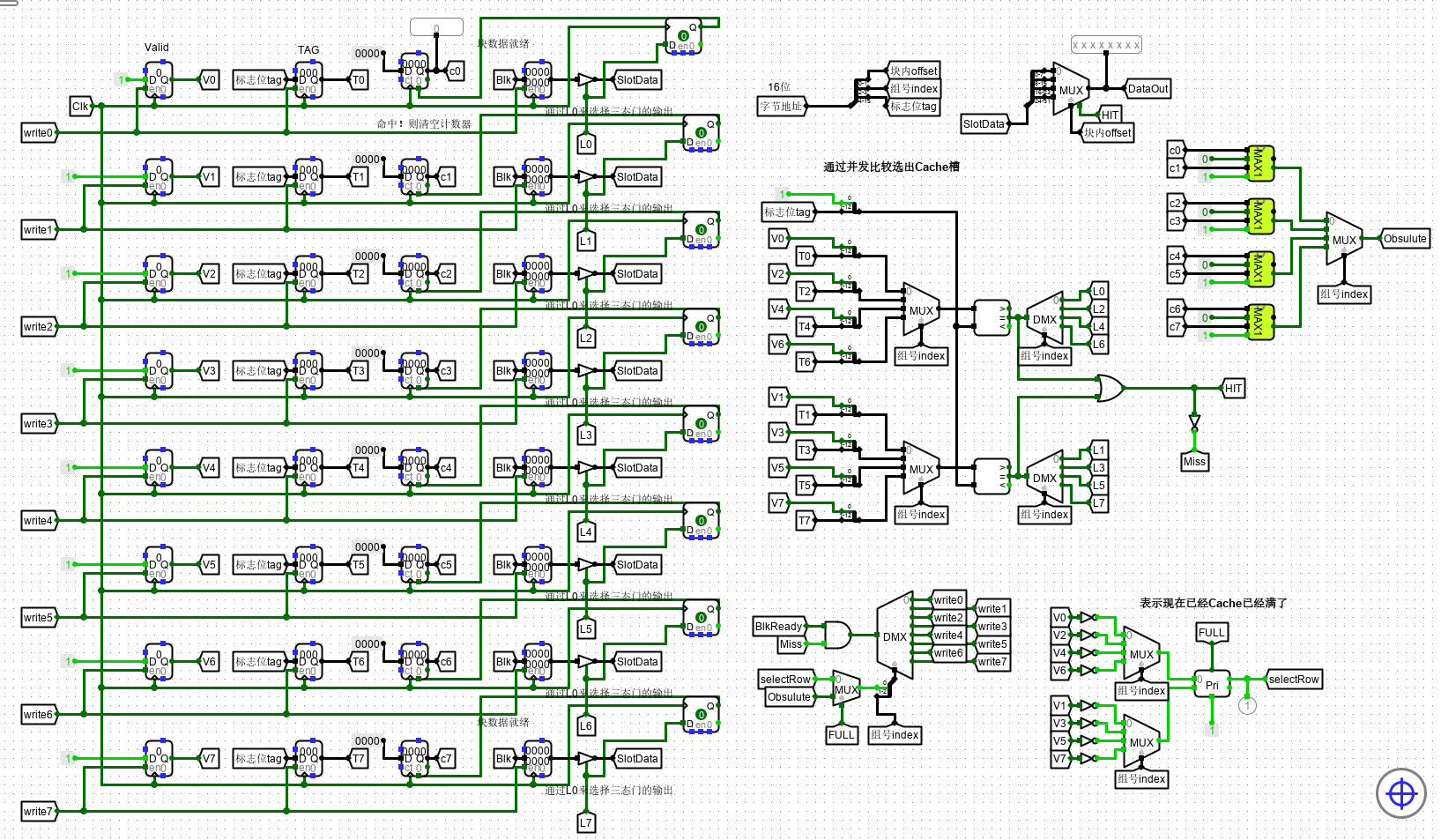
6、4 路组相联 Cache 设计
1.组相联介绍
组相联映射是直接相联映射和全相联映射的折中,或者说后两者是前者的特例。Cache 仍然分为 相联存储器CAM 和 SRAM两部分,其中 CAM 用于存放标记信息, SRAM 存放数据副本。 Cache 划分成若干组,每组若干 Cache 行。 主存地址被划分为Tag、index、offset 三部分,由索引字段 index 经过组索引译码器产生组选中译码信号(选组是采用直接映射),CAM 中对应组有效位 和 标记信息 传输到多路并发比较器,每组多少行就需要设置多少个比较器(即组内可以全选)。例如,当前组某行的标记位与主存地址中的标记位相同且有效位为 1 时,则Cache命中。

选组是直接映射,选组内的行是全映射。
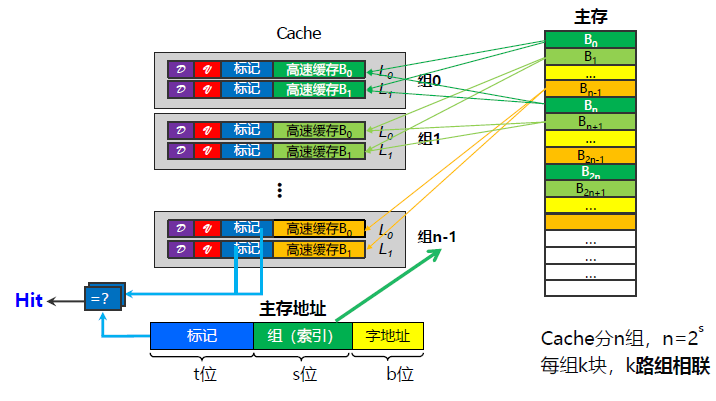
将多路并发比较结果信号与组索引译码输出信号分别进行逻辑与后得到 Cache 行选择信号(如下图) 2 路并发比较信号与 4 根组索引译码输出信号分别进行逻辑与后得到 8 根行选择信号。Cache 行选中后,读写逻辑和其他映射方式基本一致。数据淘汰时,应该在指定的组内寻找 LRU 计数器值最大的 Cache 行进行淘汰。组相联映射与全相联映射相比,其多路比较器的复杂度更低。
当每组只有一个Cache行时,只需要一个比较器,电路演变成直接相联映射。当整个Cache只有二组时,无须组索引译码器,电路演变成全相联映射。
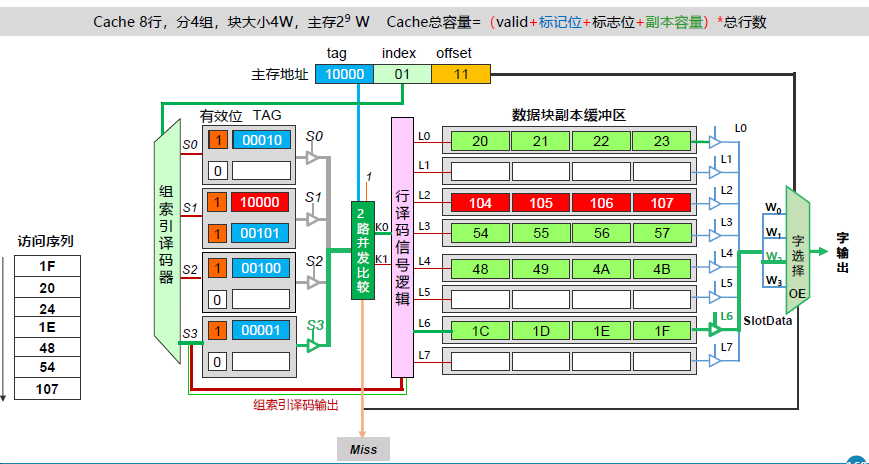
现在来说说 4 路组相联。k 路取决于每一组中有多少行。此处便是一组中有四行。
2.实验步骤
1、字节地址设计
由下图可知,输入到 4 路组相联映射的 Cache 槽前半部分(主存地址)为 16 位,主存地址被划分为Tag、index、offset 三部分。
因为块数据输入为 32 位 即 4 字节,而由于输出 Dataout 为 8 位,即按照 字节 进行输出,因此 行内字节偏移即 offset 在 Cache 槽中占 2 位。
index 指示直接映射的组号,一组中有 4 行,共有 2 组,因此为 1 位。
其余 13 位全部作为区号 tag
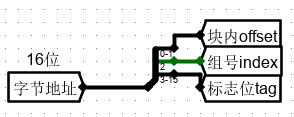
先将主存地址进行分割,作为 Cache 槽的前半部分。
2、Cache槽的设计
现在开始设计 Cache 槽。cache 主要包含四部分:Valid标志、主存 Tag 标记位、淘汰计数标记、数据副本。而我们需要考虑的主要是前三部分,并且这三部分和之后的设计息息相关。
- 当中 valid 位有效位,判断该 cache 槽是否被命中过,存入了数据;
- Tag 位是存入的主存标记位;
- 淘汰计数是一个计数器,初值为0,若行命中标志 Li 有效时,读入数据 0,达到清零的效果,若Li无效,则随着时钟频率一直进行计数。(与后面的淘汰算法密切相关)。而数据副本通过三态门缓冲器连接到总结上,这里三态门缓冲器的作用是当Li行有效时,将数据副本中输出的数据进行缓存,也就是使 8 个chche槽中的数据都可以缓存到1个Solt,这里就实现了总线的作用,十分优化。 这里给出了一个cache槽,其余的进行类似的复制。
值得注意的是:
-
为什么直接相联映射采用 L0 控制 V0、T0 的三态门,全相联直接输出?
因为此时 L0 由 V0 和 T0 决定 ,而之前采用的是 Cache 选择控制(直接相联由 字节地址中的 第 2-4 位直接选择 Lx,而全相联需要并发比较各个标志位进行选择),此处为避免死循环,就不采用三态门。
-
计数器的清空设置:
如下图,当选择该行时,需要将计数器重置。
3、写入和写出设计
-
写出设计即通过字内偏移地址 Offset 进行选择总线 Slot 上的某一字节进行输出。
-
写入设计则要当 BlkReady 数据准备完成时(测试电路中的数据准备)选择具体的cache行进行写入,而写入的前提是该行为空,即 Miss 信号有效,才能写入数据。
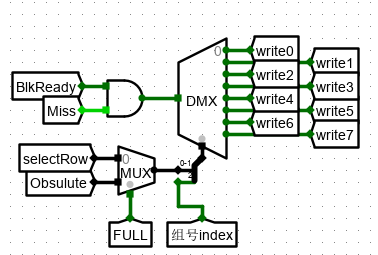
-
写入行的判断:
- 若存在空行,即 FULL 信号无效,则选择相应的空行进行写入;
- 若FULL信号有效,则选择淘汰的行进行写入。两种情况都为之后的淘汰算法中选出的行号。
4、判断是否命中。————即比较设计
对于第 3 点的写入写出需要进行判断,即比较设计来判断是否命中。
不同的映射模式最大的区别就在于比较设计上。4 路组相联因为是随机选取的 cache 行进行写入,因此没有行地址(索引),因此直接进行 4 个 cache 槽的并发比较,得到命中的 Cache 行Li,并给出 Miss 和 Hit 信号。
4 行进行比较,通过 index 进行选择哪一组进行并行输出。两组中,只要有一组成功,那么 HIT。
比较方法如图所示。
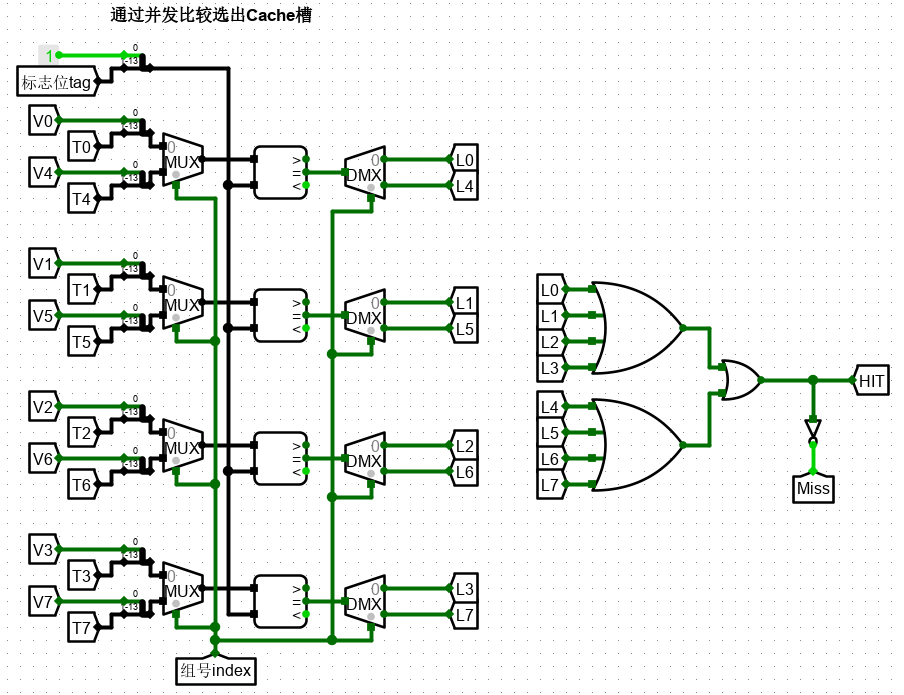
若命中,那么 HIT 信号为 1 ,则开始上文提到的 SlotData 输出显示。
若没有命中,那么 Miss 变为 1 ,开始进行淘汰算法,来选出相应的行。
5、淘汰算法
淘汰算法分为两个部分,
- 一个是当存在 cache 槽为空,空行的选择
- 一个是当 cache 槽满时,淘汰行的选择
-
槽存在空
在空行的选择中,通过优先比较器来实现,优先比较器通过比较,输出的是索引较大的非 0 行,因此先对所有行的标志位取反,取反后,若为1,则表示该行为空;若为0,则表示该行已经存在数据。若所有行都存在数据则 FULL 行满信号有效。
通过优先编码器选出索引值最大空 Cache 槽,或者输出 FULL
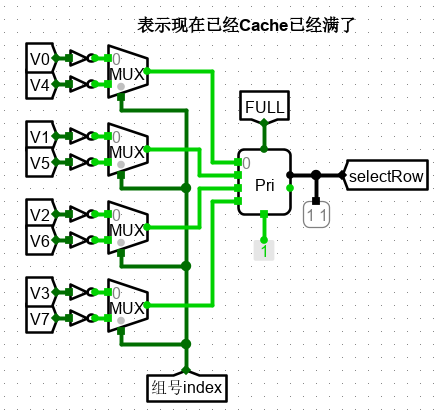
-
槽满时
在淘汰行的选择中,主要运用到LRU淘汰算法(即最近最少使用淘汰算法),由于我们在 cache 槽设计中的计数器是当行选中时清零,行为选中时随时钟频率进行计数,因此这里计数的最大值即为最少使用的cache槽。 而我们用文件中附带的归并算法,这里的归并算法是输出两个值中较大的一位的数据和索引,最后得到相应的淘汰行。
由于是要输出 二位编码,因此选择 MAX2,其内部电路如图所示
其中 Y# 是指明 二位长度( 表示 4 个)的编号。只是为了后面的译码器根据选出的 二位长度 地址进行位号选择。
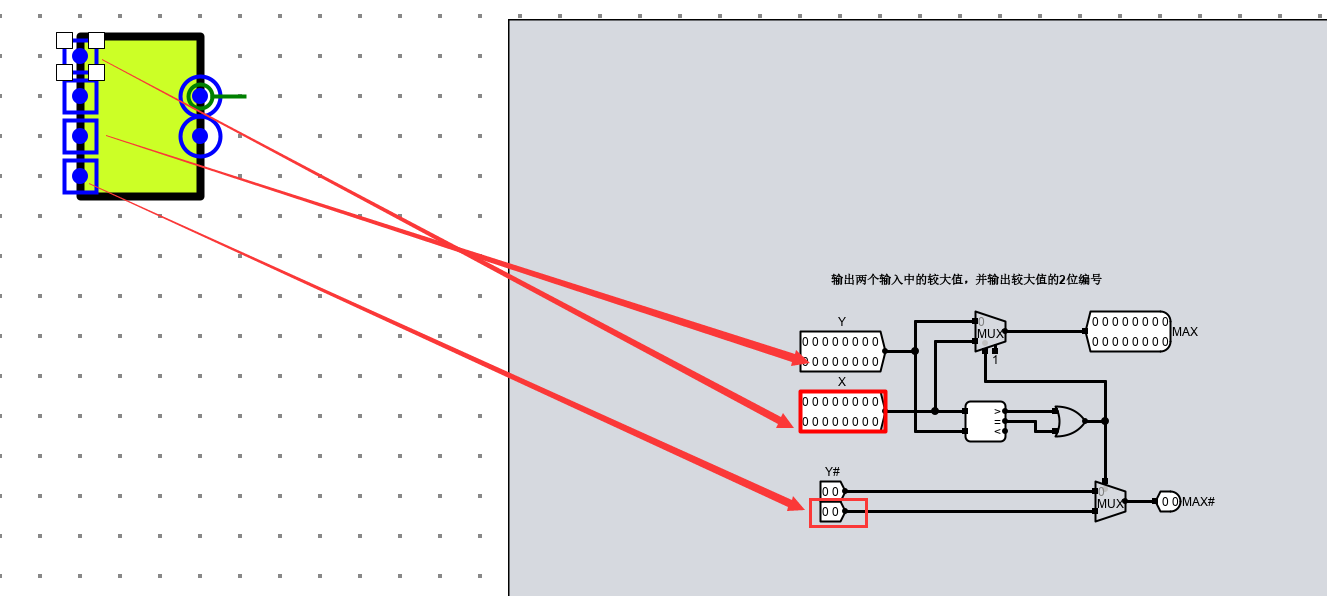
且由于此处提供的 MAX2 进行比较的数值( cnt 时钟计数)为 16 字节长度。因此计时器记录为 16位长度。
并发淘汰比较如下
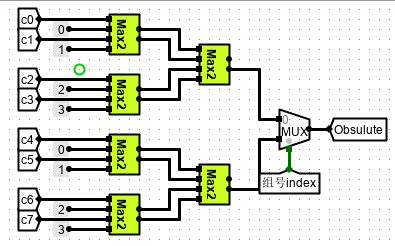
最终电路实现如下
最终成果展示
7、2 路组相联 Cache 设计
现在来说说 2 路组相联。k 路取决于每一组中有多少行。此处便是一组中有二行。
2.实验步骤
1、字节地址设计
由下图可知,输入到 4 路组相联映射的 Cache 槽前半部分(主存地址)为 16 位,主存地址被划分为Tag、index、offset 三部分。
因为块数据输入为 32 位 即 4 字节,而由于输出 Dataout 为 8 位,即按照 字节 进行输出,因此 行内字节偏移即 offset 在 Cache 槽中占 2 位。
index 指示直接映射的组号,一组中有 4 行,共有 2 组,因此为 1 位。
其余 13 位全部作为区号 tag
先将主存地址进行分割,作为 Cache 槽的前半部分。
2、Cache槽的设计
现在开始设计 Cache 槽。cache 主要包含四部分:Valid标志、主存 Tag 标记位、淘汰计数标记、数据副本。而我们需要考虑的主要是前三部分,并且这三部分和之后的设计息息相关。
- 当中 valid 位有效位,判断该 cache 槽是否被命中过,存入了数据;
- Tag 位是存入的主存标记位;
- 淘汰计数是一个计数器,初值为0,若行命中标志 Li 有效时,读入数据 0,达到清零的效果,若Li无效,则随着时钟频率一直进行计数。(与后面的淘汰算法密切相关)。而数据副本通过三态门缓冲器连接到总结上,这里三态门缓冲器的作用是当Li行有效时,将数据副本中输出的数据进行缓存,也就是使 8 个chche槽中的数据都可以缓存到1个Solt,这里就实现了总线的作用,十分优化。 这里给出了一个cache槽,其余的进行类似的复制。
值得注意的是:
-
为什么直接相联映射采用 L0 控制 V0、T0 的三态门,全相联直接输出?
因为此时 L0 由 V0 和 T0 决定 ,而之前采用的是 Cache 选择控制(直接相联由 字节地址中的 第 2-4 位直接选择 Lx,而全相联需要并发比较各个标志位进行选择),此处为避免死循环,就不采用三态门。
-
计数器的清空设置:
如下图,当选择该行时,需要将计数器重置。
-
此处清零中的毛刺问题解决: 清零动作改成同步清零,具体可以增加一个D触发器,将清零信号接输入,输出接异步清零,另外D触发器时钟触发方式请修改为上跳沿。
3、写入和写出设计
-
写出设计即通过字内偏移地址 Offset 进行选择总线 Slot 上的某一字节进行输出。
-
写入设计则要当 BlkReady 数据准备完成时(测试电路中的数据准备)选择具体的cache行进行写入,而写入的前提是该行为空,即 Miss 信号有效,才能写入数据。
-
写入行的判断:
-
若存在空行,即 FULL 信号无效,则选择相应的空行进行写入;
-
若FULL信号有效,则选择淘汰的行进行写入。两种情况都为之后的淘汰算法中选出的行号。
-
4、判断是否命中。————即比较设计
对于第 3 点的写入写出需要进行判断,即比较设计来判断是否命中。
不同的映射模式最大的区别就在于比较设计上。2 路组相联因为是随机选取的 cache 行进行写入,因此没有行地址(索引),因此直接进行 2 个 cache 槽的并发比较,得到命中的 Cache 行Li,并给出 Miss 和 Hit 信号。
4 行进行比较,通过 index 进行选择哪一组进行并行输出。两组中,只要有一组成功,那么 HIT。
比较方法如图所示。
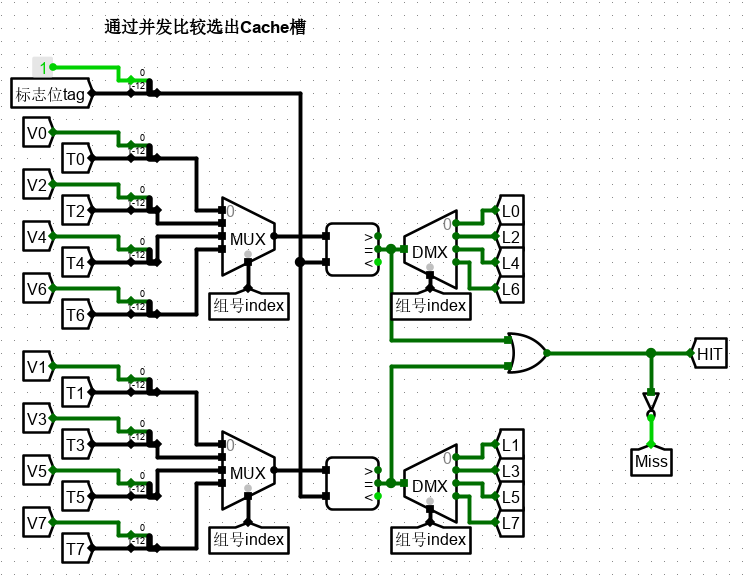
若命中,那么 HIT 信号为 1 ,则开始上文提到的 SlotData 输出显示。
若没有命中,那么 Miss 变为 1 ,开始进行淘汰算法,来选出相应的行。
5、淘汰算法
淘汰算法分为两个部分,
- 一个是当存在 cache 槽为空,空行的选择
- 一个是当 cache 槽满时,淘汰行的选择
-
槽存在空
在空行的选择中,通过优先比较器来实现,优先比较器通过比较,输出的是索引较大的非 0 行,因此先对所有行的标志位取反,取反后,若为1,则表示该行为空;若为0,则表示该行已经存在数据。若所有行都存在数据则 FULL 行满信号有效。
通过优先编码器选出索引值最大空 Cache 槽,或者输出 FULL
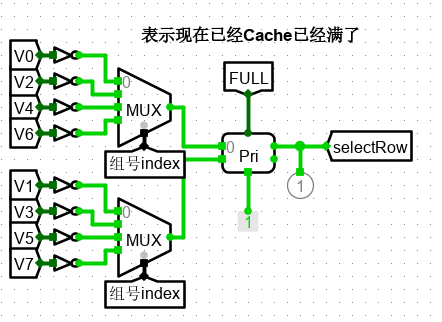
-
槽满时
在淘汰行的选择中,主要运用到LRU淘汰算法(即最近最少使用淘汰算法),由于我们在 cache 槽设计中的计数器是当行选中时清零,行为选中时随时钟频率进行计数,因此这里计数的最大值即为最少使用的cache槽。 而我们用文件中附带的归并算法,这里的归并算法是输出两个值中较大的一位的数据和索引,最后得到相应的淘汰行。
由于是要输出 二位编码,因此选择 MAX2,其内部电路如图所示
其中 Y# 是指明 二位长度( 表示 4 个)的编号。只是为了后面的译码器根据选出的 二位长度 地址进行位号选择。
MAX1 实则是对 MAX2 进行 X#、Y# 字节的更改。
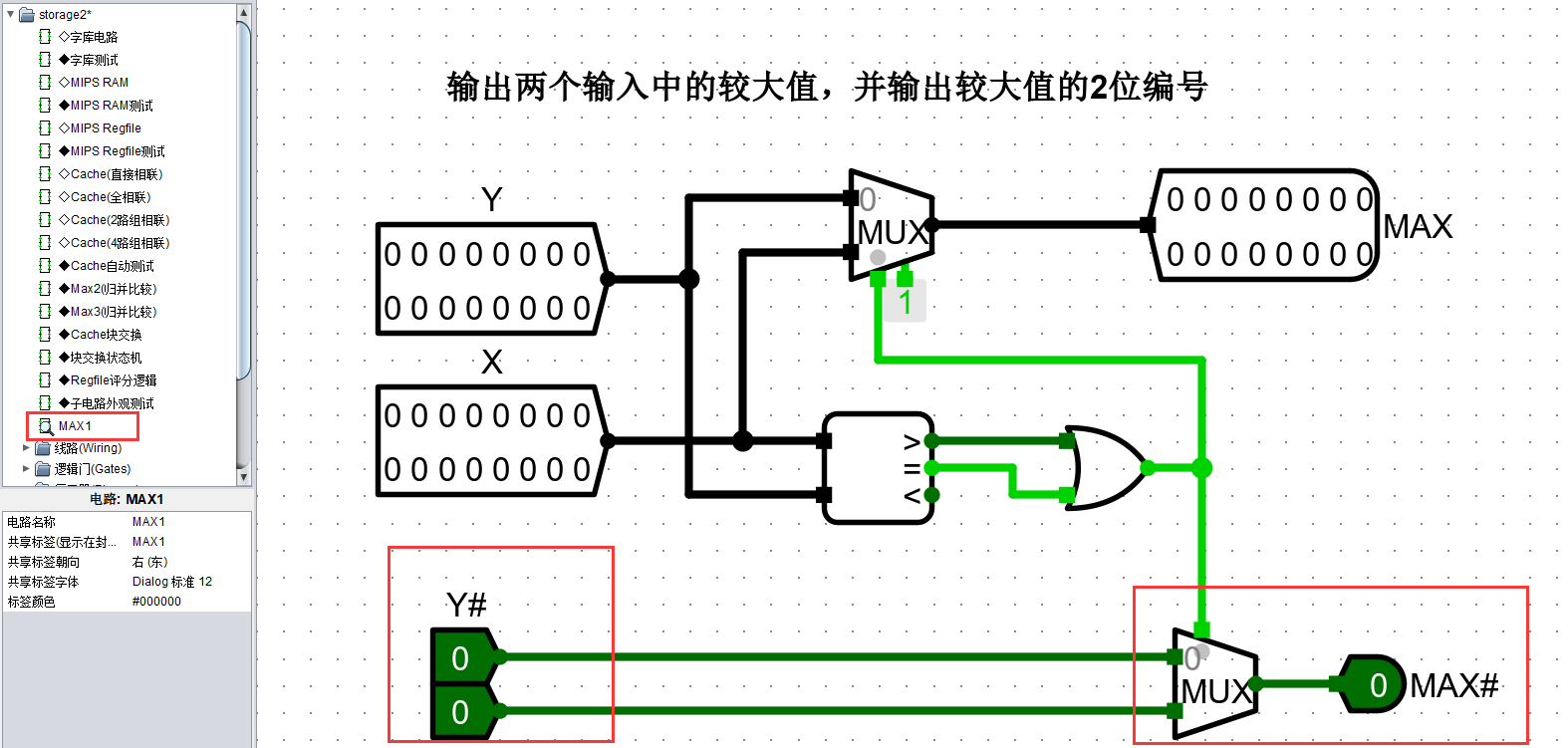
且由于此处提供的 MAX2 进行比较的数值( cnt 时钟计数)为 16 字节长度。因此计时器记录为 16位长度。
并发淘汰比较如下
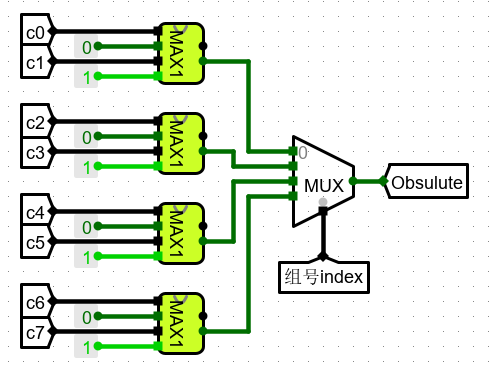
最终电路实现
测试电路
3.组相联特点
组相联应用场合
- 容量小的 cache 可采用全相联映射 或组相联映射
- Pentium CPU L1 L2 cache
- 容量大的可采用直接映射方式
- 查找速度快 ,命中率相对低
- 但cache 容量大可提高命中率
- 块设备缓存